What Is Service Discovery in Microservices

October 21, 2022
What Is Service Discovery? Why Do You Need It?
In the early days of the Internet, people had to enter a long string of IP addresses to access an online service. IP addresses were not long, but as a meaningless string of numbers, it was a challenge to remember the specific address of a particular service, which led to the invention of the domain name system. Each online service registered a domain name with a domain name provider and then established a link between the domain name and a specific IP via DNS (Domain Name System). In this way, people could simply type in a memorable domain name and access the online service on a specific IP, which was the earliest form of service discovery.
When the number of services within a company reaches a certain size (e.g. split into microservices), there is also the problem that IPs are really hard to remember, for which a service discovery system is needed. Services within the company register with the system, and other services that want to access them look up the corresponding IP address from the system, so that there is no need for a service to "remember" a complex and variable IP address.

IP address changes may confuse visitors.
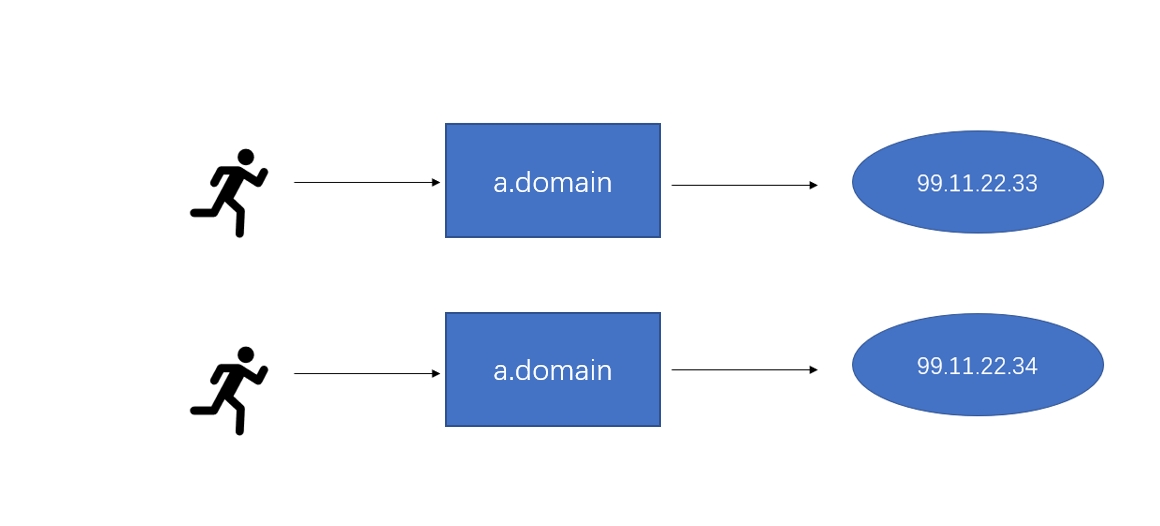
By introducing DNS as a service discovery mechanism, IP changes can now be handled flexibly.
Introduction to Common Service Discovery Systems
As a service discovery system, it needs to satisfy at least four functions:
- API for registration
- API for querying
- High availability: after all, the service discovery system is the nerve of the whole system and cannot be paralyzed or crashed
- Ecosystem: as we all know, programmers are lazy and would prefer to have a library that can interact with the APIs easily
Let's take a look at a few mainstream open-source service discovery systems on the market:
Consul
Consul is a service discovery system developed by Hashicorp, a leading open-source company. As a long-established software that released its first version on April 17, 2014, Consul has one of the richest ecosystems and even has third-party developers who develop Haskell's SDK for it. Most of Consul's SDK is just a wrapper for its HTTP API, so there is not much development work.
Consul supports registration and querying of services via the HTTP API. It supports HTTP long polling for timely data pushing during queries to avoid polling. Also, Consul supports querying the instance of the corresponding service via DNS.
The deployment of Consul is interesting in that each instance of Consul is called an agent, which can be either a client or a server. On the client side, Consul maintains a client-side state; on the server side, Consul supports distributed deployment through the consistency algorithm Raft, to achieve high availability.
Eureka
Eureka is a project open-sourced by Netflix, which is also quite old (there are traces of commits dating back to 2012.). However, the project has not been maintained for one year. Many users have migrated to Nacos, which will be mentioned below.
Eureka supports interaction via the HTTP API and the Java SDK. Many of Eureka's users were actually brought in through projects in the Java ecosystem such as Spring Cloud. Eureka's highly available design, if you want to describe it in CAP (The CAP theorem states that a distributed system can only provide two of three properties simultaneously: Consistency, Availability, and Partition tolerance) terms, is AP, which allows clients to see expired data when the network partitions, avoiding secondary disasters due to network issues.
Nacos
Nacos is a service discovery system developed by Alibaba, whose name comes from the aggregation of the first few letters of Naming and Configuration Service. Since the release of version 0.1.0 on 20 July 2018, Nacos has now evolved to version 2.1.
Like many of Alibaba's open-source projects, Nacos is quite popular among Java developers in China, and its popularity is even quite a bit greater than Eureka.
It supports registration and querying of services via the HTTP API and SDKs such as Java/Go/Python/NodeJS/C#. Currently, Nacos developers are also working on new APIs based on gRPC. For the HTTP API, Nacos currently only supports polling for a list of services. So Nacos officially prefers the SDK approach, which is a polling + UDP-based push approach with better real-time performance. Nacos is also working on new APIs based on gRPC, which will introduce server-side push capabilities, a great benefit for those systems that do not have access to the SDK.
The high availability of Nacos is partly due to the persistence capabilities provided in the client SDK, and partly due to the consistency of the server side through both Raft and Distro protocols.
Common Interfacing Methods and Their Advantages and Disadvantages
Leaving aside private protocols, service discovery interfacing methods can be divided into three categories:
- HTTP polling
- DNS
- HTTP long polling or gRPC server streaming
HTTP polling is simple to implement but is not real-time.
The performance overhead of DNS is minimal. DNS is also not real-time due to the DNS cache, and has the advantage of being a widely accepted, implementation-independent set of standards. However, there are two sides to the coin, which means that the service discovery system cannot add additional fields to the DNS response unless the Additional field in the DNS response is used, but this would require special handling by the client.
HTTP long polling or gRPC server streaming is the most real-time of the three. Since they are both HTTP-based, the response can be easily customized. The disadvantage is that they are relatively difficult to implement on the client side.
How APISIX Interfaces with Service Discovery Systems
As a cloud-native gateway, APISIX supports fetching upstream nodes from the service discovery system and is designed to support interfacing with the service discovery system on both the data plane and the control plane.
Data Plane
APISIX supports integrating with DNS, Eureka, Consul (KV mode), Nacos, and K8s on the data plane.
When interfacing with DNS services, APISIX will use the SRV or A/AAAA records of DNS to get the specific upstream node of a service. When a request is made to access the upstream, it will first try to fetch it from the DNS cache. If not, it will initiate a DNS query to get the specific IP address inside the corresponding record.
As for the other service discovery types, they are synchronized in the background. When a request is made to access the upstream, the part of the data corresponding to the service name is fetched from the data currently synchronized. For K8s and Consul KV, we can get the changed IP address in real time this way, as they support HTTP long polling. For Eureka and Nacos we are currently only polling for data.
Control Plane
APISIX also supports service discovery on the control plane. We are working on apisix-seed, which will synchronize data from the service discovery system to etcd so that the data plane can synchronize the latest upstream nodes from etcd.
We have now implemented support for Nacos and Zookeeper on the control plane. Since the service discovery support on the control plane is implemented via the official SDK, it has advantages that are not available with the normal HTTP method. For example, in the apisix-seed implementation of Nacos, we support UDP-based pushing, so the data is more time-efficient than HTTP polling.
Advantages of APISIX Support for Service Discovery Scenarios
By integrating service discovery directly on the gateway, you can greatly simplify the workload of bringing your services online. Configure APISIX to interface with your service discovery system and then let APISIX do the rest for you. For example, if your company is using Nacos as a service discovery system, all you need to do is configure APISIX to enable Nacos service discovery and then simply configure the service name upstream of APISIX and APISIX will automatically fetch the specific IP node that corresponds to that upstream.
This is an advantage that can significantly reduce the amount of work required when migrating a gateway, for example, from Spring Cloud Gateway to APISIX. If the Spring Cloud Gateway is used to apply Eureka or Nacos for service discovery, the transition to the new system can be done by simply enabling support for Eureka or Nacos within APISIX.
Huan Bei Loan has extensive experience in this area, and the replacement of the Spring Cloud Gateway is intended to further improve stability, supervision, accuracy, and effectiveness.
To quote the original text of Huan Bei Loan:
As a business, the cost is still the principle to be considered. In the wild growth phase, it may be necessary to boost the business's growth as quickly as possible. However, in the current environment, the priority is definitely the cost within budget. In this case, efficiency and cost can only ever be preserved in one way or another. So with limited costs, companies will talk less about technological advancement. In the selection process, the technical staff will consider less how much impact the technology they choose will have on the team, how much benefit it will bring to the existing operations and architecture, etc., but more from the cost perspective.
In addition, APISIX supports the simultaneous configuration of multiple service discoveries. Many companies, for historical reasons, may have multiple service discovery systems. For example, as far as I know, some companies will have both the old Eureka service discovery and the new Nacos service discovery. APISIX simply needs to enable both Eureka and Nacos to cope with this situation.
If you are currently configuring upstream nodes directly on APISIX, you can also consider deploying a separate service discovery system and having the service discovery system store the specific node configuration instead. The benefit of moving the upstream node configuration, from APISIX, to a dedicated service discovery system is that the client can do the service registration itself, and the dedicated service discovery system often provides additional functionality such as richer health checks.
In the future, we will also support the integration of various service registration and discovery components on the APISIX Ingress Controller to make it easier for users to use. At that time, users will be not only able to specify the endpoints of K8s service as upstream nodes on APISIX Ingress Controller, but also able to integrate the nodes obtained by service discovery.