Part 2: How to Build a Microservices API gateway using OpenResty
API7.ai
February 2, 2023
After understanding a microservices API gateway's core components and abstractions, it's time to start and implement the technical selection. Today, we'll look at the technical selection of the four core components respectively: storage, routing, schema, and plugins.
Storage
As mentioned in the previous article, storage is a very critical basic component at the bottom, which will affect the core issues such as how to synchronize the configuration, how to scale the cluster, and how to guarantee high availability, so we put it at the very beginning of the selection process.
Let's take a look at where the existing API gateways store their data: Kong in PostgreSQL or Cassandra. And Orange, also based on OpenResty, in MySQL. However, these options have many drawbacks.
First, storage needs to be a separate high-availability solution. PostgreSQL and MySQL databases have their own high-availability solution. Still, it would help if you also had DBA and machine resources, and it is difficult to do a quick switchover in case of failure.
Second, we can only poll the database to get configuration changes and cannot do pushing. Again, this will increase database resource consumption and reduce changes' real-time performance.
Third, you must maintain your historical versions and consider rollbacks and upgrades. For example, if a user releases a change, there may be subsequent rollback operations, at which point you need to do your diff between the two versions at the code level for configuration rollback. Also, when the system is upgraded, it may modify the database's table structure, so the code must consider the compatibility of the old and new versions and data upgrades.
Fourth, it raises the complexity of the code. In addition to implementing the functionality of the gateway, you need to patch the first three defects of the code, which obviously makes the code much less readable.
Fifth, it increases the difficulty of deployment and operation, and maintenance. Deploying and maintaining a relational database is not a simple task, and it is even more complicated if it is a database cluster. We can't do rapid scaling.
How should we choose for these cases?
Let's go back to the original requirements of the API gateway, where simple configuration information is stored, such as URI, plugin parameters, upstream addresses, etc. No complex join operations are involved, and no strict transaction guarantees are required. In this case, using a relational database is not "killing the chicken with a slaughtering knife," right?
In fact, minimizing the use of K8s and keeping it closer, etcd, is the right choice.
- The number of changes per second in the configuration data of the API gateway is not large, which enables enough performance for etcd.
- Clustering and dynamic scaling are inherent advantages of etcd.
- etcd also has a
watchinterface, so you don't have to poll to get changes.
Another thing that proves etcd's reliability is that it's already the default choice for saving configurations in the K8s system and has been validated for many more complex scenarios than API gateways.
Routing
Routing is also an essential technical selection, and all requests are filtered by the route to the list of plugins that need to be loaded, run one by one, and then forwarded to the specified upstream. However, considering that there may be more routing rules, we need to focus on the algorithm's time complexity for the technical selection of routing here.
Let's start by looking at what routes are readily available under OpenResty. Then, as usual, let's look up each of them in the awesome-resty project, which has special routing libraries:
• lua-resty-route — A URL routing library for OpenResty supporting multiple route matchers, middleware, and HTTP and WebSockets handlers to mention a few of its features • router.lua — A barebones router for Lua, it matches URLs and executes Lua functions • lua-resty-r3 — libr3 OpenResty implementation, libr3 is a high-performance path dispatching library. It compiles your route paths into a prefix tree (trie). By using the constructed prefix trie in the start-up time, you may dispatch your routes with efficiency • lua-resty-libr3 — High-performance path dispatching library base on libr3 for OpenResty
As you can see, this contains the implementations of the four routing libraries. Unfortunately, the first two routings are pure Lua implementations, which are relatively simple, so there are quite a few missing features that are not yet up to the generation requirements.
The latter two libraries are actually based on the C library libr3 with a layer of wrapping using FFI, while libr3 itself uses a prefix tree. This algorithm has nothing to do with the number N of rules stored but only with the length K of the matching data, so the time complexity is O(K).
However, libr3 has its drawbacks. Its matching rules differ from those of the familiar NGINX location, and it does not support callbacks. This leaves us with no way to set the conditions for routing based on request headers, cookies, and NGINX variables, which is obviously not flexible enough for API gateway scenarios.
However, although our attempts to find a usable routing library from awesome-resty were unsuccessful, the libr3 implementation points us in a new direction: implementing prefix trees and FFI wrappers in C, which should come close to the optimal solution in terms of time complexity and code performance.
As it happens, the authors of Redis have open-sourced a C implementation of the radix tree, which is a compressed prefix tree. Following the trail, we can also find the FFI wrapper library for rax available in OpenResty, which has the following sample code:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
As you can see, lua-resty-radixtree supports multiple dimensions for route lookup based on URI, host, HTTP method, HTTP header, NGINX variables, IP address, etc. Also, the time complexity of the base tree is O(K), which is much more efficient than the commonly used traversal + hash cache approach.
Schema
Choosing schema is much easier. The lua-rapidjson we introduced earlier is a very good choice. You don't need to write one for this part; the JSON schema is powerful enough. The following is a simple example.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Plugin
With the above foundation of storage, routing, and schema, it is much more apparent how the upper layer of plugins should be implemented. There are no ready-made open-source libraries to use in plugins. We need to implement them ourselves. When designing plugins, there are three main aspects that we need to consider clearly.
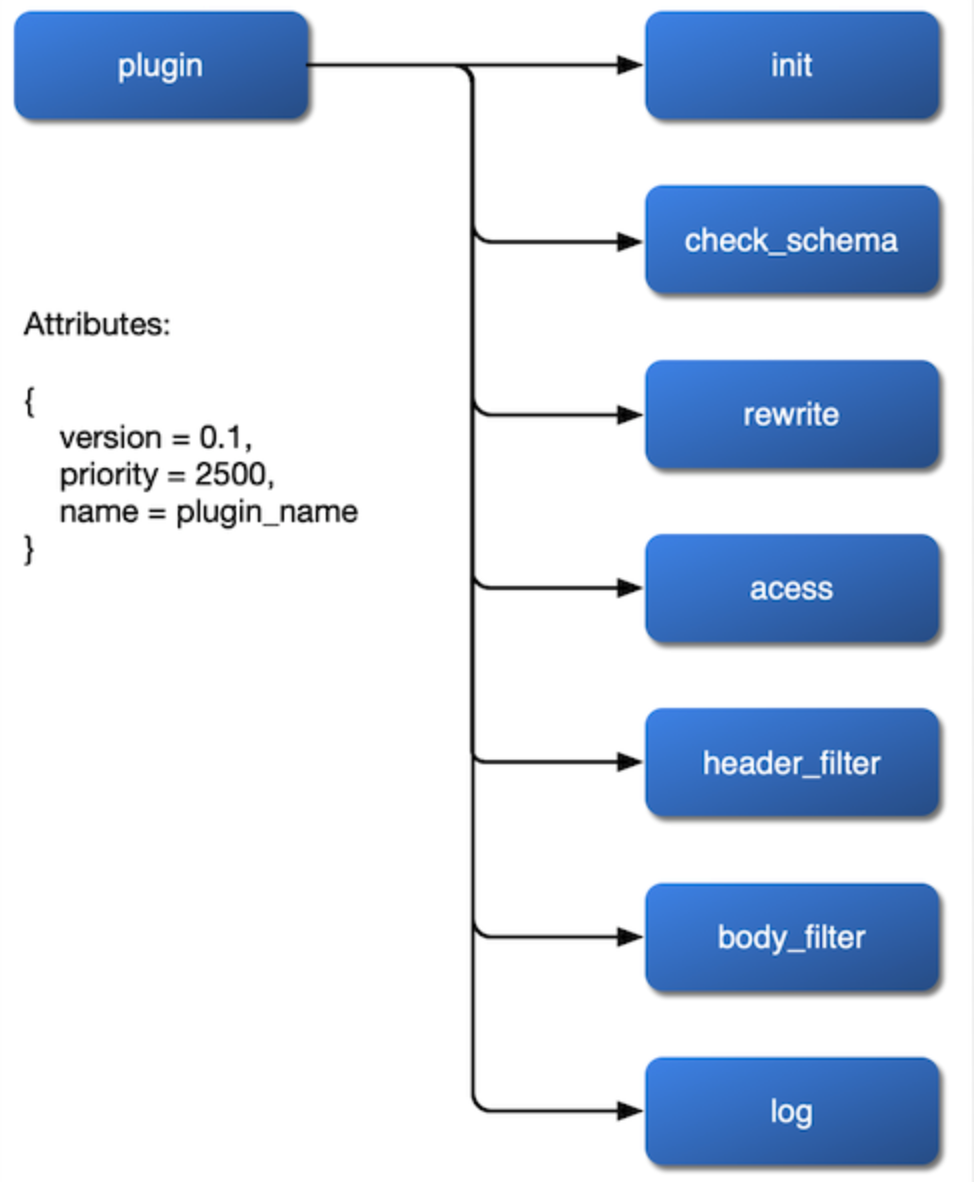
The first thing is how to mount it. We want the plugin to mount to the rewrite, access, header filer, body filter, and log phases and even set up its load-balancing algorithm in the balancer stage. So, we should expose these stages in the NGINX configuration file and leave the interface open in implementing the plugin.
The next is how to get the configuration changes. Since there are no relational database constraints, changes to plugin parameters can be implemented through etcd's watch, which makes the overall framework code logic much more transparent and easier to understand.
Finally, we need to consider the priority of plugins. For example, which plugin should be executed first? for authentication or limiting flow and speed? When there is a race condition between a plugin bound to route and another plugin bound to service, which one should take precedence? These are all things we need to consider in place.
After sorting out these three issues of the plugin, we can get a flowchart of the plugin's internals:
{kind=link}
Infrastructure
Naturally, when these critical components of the microservices API gateway are determined, the processing flow of user requests will be settled. Here I draw a diagram to show this process:
Diagram of user requests' processing flow
{kind=link}
From this figure, we can see that when a user requests to enter the API gateway,
- First of all, the routing rules will be matched according to the request methods, URI, host, and request header conditions. If you hit a routing rule, you will get the corresponding plugin list from etcd.
- Then, it intersects with the locally opened plugin list to get the final plugin list that can be run.
- And then run the plugins one by one according to their priority.
- Finally, the request is sent to the upstream according to the upstream health check and load balancing algorithm.
We will be ready to write specific code when the architecture design is completed. This is actually like building a house. Only after you have the blueprint and solid foundation can you do the concrete work of building bricks and tiles.
Summary
In fact, through the study of these two articles, we have done the two most important things of product positioning and technology selection, which are more critical than the specific coding implementation. Please consider and choose more carefully.
So, have you ever used API gateway in your actual work? How does your company choose the API gateway? Welcome to leave a message and share your experience and gains with me. You are also welcome to share this article with more people so that you can communicate and make progress.
Previous: Part 1: How to Build a Microservices API gateway using OpenResty Next: Part 3: How to Build a Microservices API Gateway Using OpenResty