Was ist Service Discovery in Microservices?

October 21, 2022
Was ist Service Discovery? Warum wird sie benötigt?
In den Anfängen des Internets mussten Menschen lange IP-Adressen eingeben, um auf einen Online-Dienst zuzugreifen. IP-Adressen waren zwar nicht lang, aber als bedeutungslose Zahlenfolge war es eine Herausforderung, sich die spezifische Adresse eines bestimmten Dienstes zu merken, was zur Erfindung des Domain Name Systems (DNS) führte. Jeder Online-Dienst registrierte einen Domain-Namen bei einem Domain-Name-Provider und stellte dann über DNS (Domain Name System) eine Verbindung zwischen dem Domain-Namen und einer spezifischen IP her. Auf diese Weise konnten Benutzer einfach einen einprägsamen Domain-Namen eingeben und auf den Online-Dienst unter einer bestimmten IP zugreifen. Dies war die früheste Form der Service Discovery.
Wenn die Anzahl der Dienste innerhalb eines Unternehmens eine bestimmte Größe erreicht (z. B. durch Aufteilung in Microservices), gibt es auch das Problem, dass IP-Adressen schwer zu merken sind, weshalb ein Service-Discovery-System benötigt wird. Dienste innerhalb des Unternehmens registrieren sich bei diesem System, und andere Dienste, die auf sie zugreifen möchten, suchen die entsprechende IP-Adresse im System nach. Auf diese Weise muss ein Dienst keine komplexe und sich ändernde IP-Adresse "merken".

IP-Adressänderungen können Besucher verwirren.
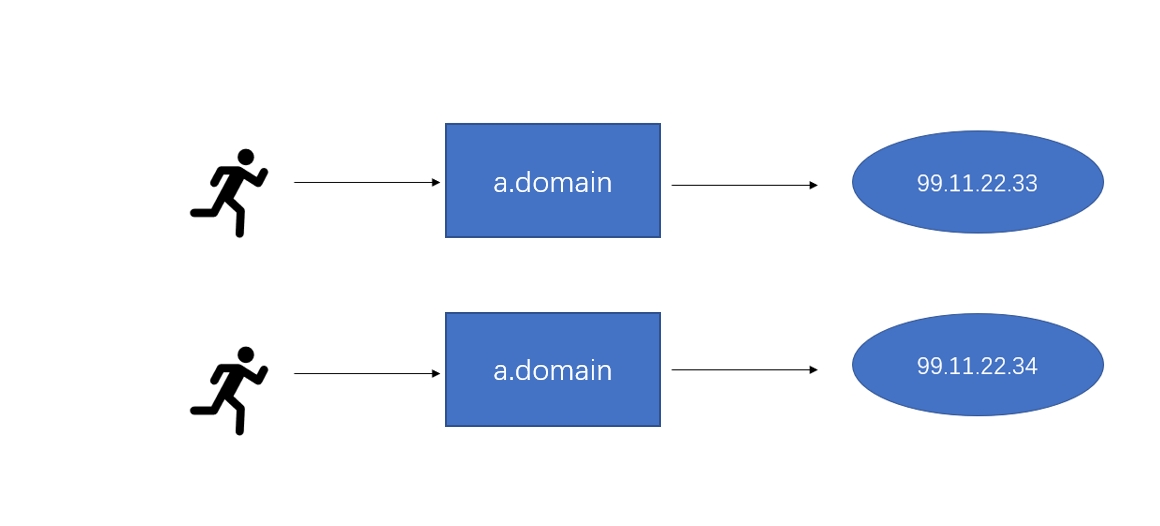
Durch die Einführung von DNS als Service-Discovery-Mechanismus können IP-Änderungen nun flexibel gehandhabt werden.
Einführung in gängige Service-Discovery-Systeme
Als Service-Discovery-System muss es mindestens vier Funktionen erfüllen:
- API für die Registrierung
- API für Abfragen
- Hochverfügbarkeit: Schließlich ist das Service-Discovery-System das Nervenzentrum des gesamten Systems und darf nicht ausfallen oder abstürzen
- Ökosystem: Wie wir alle wissen, sind Programmierer faul und bevorzugen eine Bibliothek, die einfach mit den APIs interagieren kann
Schauen wir uns einige der gängigen Open-Source-Service-Discovery-Systeme auf dem Markt an:
Consul
Consul ist ein Service-Discovery-System, das von Hashicorp, einem führenden Open-Source-Unternehmen, entwickelt wurde. Als langjährige Software, deren erste Version am 17. April 2014 veröffentlicht wurde, verfügt Consul über eines der reichhaltigsten Ökosysteme und hat sogar Drittanbieter, die SDKs für Haskell entwickeln. Die meisten SDKs von Consul sind lediglich Wrapper für die HTTP-API, sodass der Entwicklungsaufwand gering ist.
Consul unterstützt die Registrierung und Abfrage von Diensten über die HTTP-API. Es unterstützt HTTP-Long-Polling für zeitnahes Daten-Pushing bei Abfragen, um Polling zu vermeiden. Außerdem unterstützt Consul die Abfrage der Instanz des entsprechenden Dienstes über DNS.
Die Bereitstellung von Consul ist interessant, da jede Instanz von Consul als Agent bezeichnet wird, der entweder ein Client oder ein Server sein kann. Auf der Client-Seite verwaltet Consul einen Client-Zustand; auf der Server-Seite unterstützt Consul die verteilte Bereitstellung durch den Konsistenzalgorithmus Raft, um Hochverfügbarkeit zu erreichen.
Eureka
Eureka ist ein von Netflix open-sourciertes Projekt, das ebenfalls recht alt ist (es gibt Commits aus dem Jahr 2012). Das Projekt wird jedoch seit einem Jahr nicht mehr gepflegt. Viele Benutzer sind zu Nacos migriert, das weiter unten erwähnt wird.
Eureka unterstützt die Interaktion über die HTTP-API und das Java-SDK. Viele Eureka-Benutzer wurden tatsächlich durch Projekte im Java-Ökosystem wie Spring Cloud gewonnen. Das hochverfügbare Design von Eureka, wenn man es in CAP-Begriffen (Das CAP-Theorem besagt, dass ein verteiltes System nur zwei von drei Eigenschaften gleichzeitig bieten kann: Konsistenz, Verfügbarkeit und Partitionstoleranz) beschreiben möchte, ist AP, was es Clients ermöglicht, veraltete Daten zu sehen, wenn Netzwerkpartitionen auftreten, um sekundäre Katastrophen aufgrund von Netzwerkproblemen zu vermeiden.
Nacos
Nacos ist ein Service-Discovery-System, das von Alibaba entwickelt wurde. Der Name setzt sich aus den ersten Buchstaben von Naming und Configuration Service zusammen. Seit der Veröffentlichung von Version 0.1.0 am 20. Juli 2018 hat sich Nacos nun zu Version 2.1 weiterentwickelt.
Wie viele Open-Source-Projekte von Alibaba ist Nacos bei Java-Entwicklern in China sehr beliebt, und seine Popularität ist sogar deutlich höher als die von Eureka.
Es unterstützt die Registrierung und Abfrage von Diensten über die HTTP-API und SDKs wie Java/Go/Python/NodeJS/C#. Derzeit arbeiten die Nacos-Entwickler auch an neuen APIs basierend auf gRPC. Für die HTTP-API unterstützt Nacos derzeit nur das Polling einer Liste von Diensten. Daher bevorzugt Nacos offiziell den SDK-Ansatz, der ein Polling + UDP-basiertes Push-Verfahren mit besserer Echtzeitfähigkeit ist. Nacos arbeitet auch an neuen APIs basierend auf gRPC, die server-seitige Push-Fähigkeiten einführen werden, was ein großer Vorteil für Systeme ist, die keinen Zugriff auf das SDK haben.
Die Hochverfügbarkeit von Nacs ist teilweise auf die Persistenzfähigkeiten zurückzuführen, die im Client-SDK bereitgestellt werden, und teilweise auf die Konsistenz der Server-Seite durch die Protokolle Raft und Distro.
Gängige Schnittstellenmethoden und ihre Vor- und Nachteile
Abgesehen von privaten Protokollen können die Schnittstellenmethoden für Service Discovery in drei Kategorien unterteilt werden:
- HTTP-Polling
- DNS
- HTTP-Long-Polling oder gRPC-Server-Streaming
HTTP-Polling ist einfach zu implementieren, aber nicht in Echtzeit.
Der Leistungsaufwand von DNS ist minimal. DNS ist aufgrund des DNS-Caches ebenfalls nicht in Echtzeit und hat den Vorteil, dass es ein weit verbreiteter, implementierungsunabhängiger Satz von Standards ist. Es gibt jedoch zwei Seiten der Medaille, was bedeutet, dass das Service-Discovery-System keine zusätzlichen Felder zur DNS-Antwort hinzufügen kann, es sei denn, das Additional-Feld in der DNS-Antwort wird verwendet, aber dies würde eine spezielle Behandlung durch den Client erfordern.
HTTP-Long-Polling oder gRPC-Server-Streaming ist das Echtzeitfähigste der drei. Da beide auf HTTP basieren, kann die Antwort leicht angepasst werden. Der Nachteil ist, dass sie auf der Client-Seite relativ schwierig zu implementieren sind.
Wie APISIX mit Service-Discovery-Systemen interagiert
Als Cloud-native Gateway unterstützt APISIX das Abrufen von Upstream-Knoten aus dem Service-Discovery-System und ist so konzipiert, dass es die Interaktion mit dem Service-Discovery-System sowohl auf der Datenebene als auch auf der Steuerungsebene unterstützt.
Datenebene
APISIX unterstützt die Integration mit DNS, Eureka, Consul (KV-Modus), Nacos und K8s auf der Datenebene.
Bei der Interaktion mit DNS-Diensten verwendet APISIX die SRV- oder A/AAAA-Records von DNS, um den spezifischen Upstream-Knoten eines Dienstes zu erhalten. Wenn eine Anfrage zum Zugriff auf den Upstream gestellt wird, wird zunächst versucht, ihn aus dem DNS-Cache abzurufen. Wenn nicht, wird eine DNS-Abfrage initiiert, um die spezifische IP-Adresse innerhalb des entsprechenden Records zu erhalten.
Bei den anderen Service-Discovery-Typen erfolgt die Synchronisierung im Hintergrund. Wenn eine Anfrage zum Zugriff auf den Upstream gestellt wird, wird der Teil der Daten, der dem Dienstnamen entspricht, aus den aktuell synchronisierten Daten abgerufen. Für K8s und Consul KV können wir die geänderte IP-Adresse auf diese Weise in Echtzeit erhalten, da sie HTTP-Long-Polling unterstützen. Für Eureka und Nacos führen wir derzeit nur Polling für Daten durch.
Steuerungsebene
APISIX unterstützt auch Service Discovery auf der Steuerungsebene. Wir arbeiten an apisix-seed, das Daten aus dem Service-Discovery-System mit etcd synchronisiert, sodass die Datenebene die neuesten Upstream-Knoten von etcd synchronisieren kann.
Wir haben jetzt die Unterstützung für Nacos und Zookeeper auf der Steuerungsebene implementiert. Da die Service-Discovery-Unterstützung auf der Steuerungsebene über das offizielle SDK implementiert wird, hat sie Vorteile, die mit der normalen HTTP-Methode nicht verfügbar sind. Zum Beispiel unterstützen wir in der apisix-seed-Implementierung von Nacos UDP-basiertes Pushen, sodass die Daten zeitnaher sind als bei HTTP-Polling.
Vorteile der APISIX-Unterstützung für Service-Discovery-Szenarien
Durch die direkte Integration von Service Discovery in das Gateway können Sie den Arbeitsaufwand für die Bereitstellung Ihrer Dienste erheblich vereinfachen. Konfigurieren Sie APISIX für die Interaktion mit Ihrem Service-Discovery-System und lassen Sie APISIX den Rest für Sie erledigen. Wenn Ihr Unternehmen beispielsweise Nacos als Service-Discovery-System verwendet, müssen Sie lediglich APISIX so konfigurieren, dass es die Nacos-Service-Discovery aktiviert, und dann einfach den Dienstnamen upstream von APISIX konfigurieren. APISIX holt automatisch den spezifischen IP-Knoten ab, der diesem Upstream entspricht.
Dies ist ein Vorteil, der den Arbeitsaufwand bei der Migration eines Gateways, z. B. von Spring Cloud Gateway zu APISIX, erheblich reduzieren kann. Wenn das Spring Cloud Gateway verwendet wird, um Eureka oder Nacos für die Service Discovery anzuwenden, kann der Übergang zum neuen System einfach durch die Aktivierung der Unterstützung für Eureka oder Nacos innerhalb von APISIX erfolgen.
Huan Bei Loan hat umfangreiche Erfahrung in diesem Bereich, und der Ersatz des Spring Cloud Gateways soll die Stabilität, Überwachung, Genauigkeit und Effektivität weiter verbessern.
Zitat aus dem Originaltext von Huan Bei Loan:
Als Unternehmen ist die Kostenkontrolle immer noch das zu beachtende Prinzip. In der Wachstumsphase mag es notwendig sein, das Geschäftswachstum so schnell wie möglich zu fördern. In der aktuellen Umgebung ist jedoch die Kostenkontrolle innerhalb des Budgets definitiv die Priorität. In diesem Fall können Effizienz und Kosten nur auf eine oder andere Weise erhalten werden. Daher werden Unternehmen bei begrenzten Kosten weniger über technologischen Fortschritt sprechen. Bei der Auswahl werden die technischen Mitarbeiter weniger darüber nachdenken, wie viel Einfluss die gewählte Technologie auf das Team haben wird, wie viel Nutzen sie für die bestehenden Operationen und die Architektur bringen wird usw., sondern mehr aus der Kostenperspektive.
Darüber hinaus unterstützt APISIX die gleichzeitige Konfiguration mehrerer Service-Discovery-Systeme. Viele Unternehmen haben aus historischen Gründen möglicherweise mehrere Service-Discovery-Systeme. Beispielsweise haben einige Unternehmen sowohl das alte Eureka-Service-Discovery-System als auch das neue Nacos-Service-Discovery-System. APISIX muss lediglich sowohl Eureka als auch Nacos aktivieren, um mit dieser Situation umzugehen.
Wenn Sie derzeit Upstream-Knoten direkt auf APISIX konfigurieren, können Sie auch in Betracht ziehen, ein separates Service-Discovery-System bereitzustellen und das Service-Discovery-System die spezifische Knotenkonfiguration speichern zu lassen. Der Vorteil der Verlagerung der Upstream-Knotenkonfiguration von APISIX auf ein dediziertes Service-Discovery-System besteht darin, dass der Client die Dienstregistrierung selbst durchführen kann und das dedizierte Service-Discovery-System oft zusätzliche Funktionen wie umfangreichere Gesundheitsprüfungen bietet.
In Zukunft werden wir auch die Integration verschiedener Service-Registrierungs- und Discovery-Komponenten auf dem APISIX Ingress Controller unterstützen, um die Nutzung für Benutzer zu erleichtern. Zu diesem Zeitpunkt können Benutzer nicht nur die Endpunkte des K8s-Dienstes als Upstream-Knoten auf dem APISIX Ingress Controller angeben, sondern auch die Knoten integrieren, die durch Service Discovery erhalten werden.