マイクロサービスにおけるService Discoveryとは何か

October 21, 2022
サービスディスカバリとは何か?なぜ必要なのか?
インターネットの初期には、オンラインサービスにアクセスするために長いIPアドレスの文字列を入力する必要がありました。IPアドレス自体は長くはありませんが、意味のない数字の羅列であるため、特定のサービスのアドレスを覚えるのは困難でした。これがドメインネームシステムの発明につながりました。各オンラインサービスはドメインネームプロバイダーにドメイン名を登録し、DNS(ドメインネームシステム)を介してドメイン名と特定のIPアドレスをリンクさせました。これにより、人々は覚えやすいドメイン名を入力するだけで、特定のIPアドレスのオンラインサービスにアクセスできるようになりました。これがサービスディスカバリの最初の形態です。
企業内のサービス数がある程度の規模(例えばマイクロサービスに分割された場合)に達すると、IPアドレスを覚えるのが非常に困難になるという問題も発生します。そのため、サービスディスカバリシステムが必要となります。企業内のサービスはこのシステムに登録し、それにアクセスしたい他のサービスはシステムから対応するIPアドレスを検索します。これにより、サービスが複雑で変動するIPアドレスを「覚える」必要がなくなります。

IPアドレスの変更は訪問者を混乱させる可能性があります。
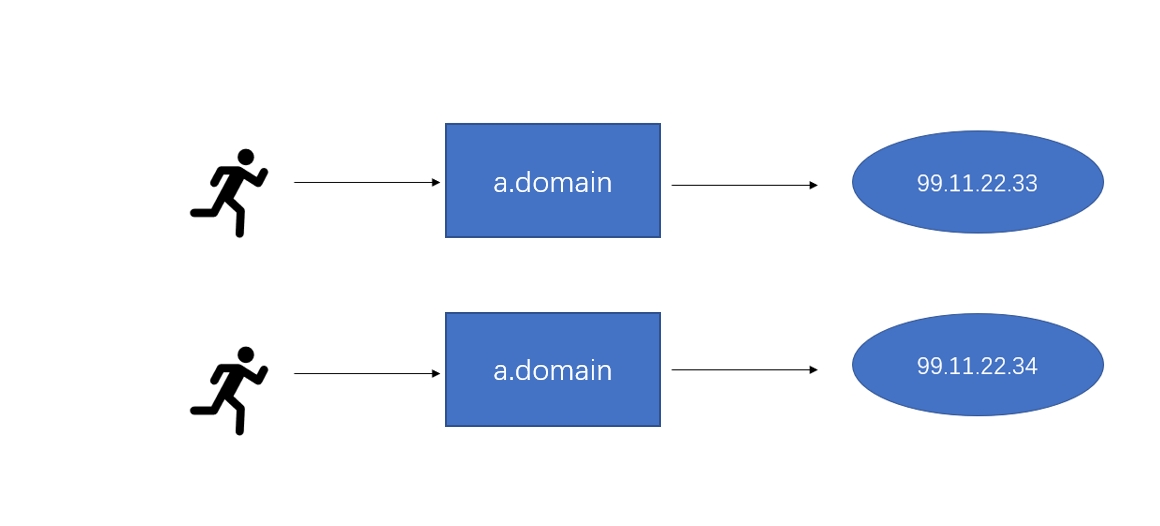
DNSをサービスディスカバリメカニズムとして導入することで、IP変更を柔軟に処理できるようになりました。
一般的なサービスディスカバリシステムの紹介
サービスディスカバリシステムとして、少なくとも4つの機能を満たす必要があります:
- 登録用のAPI
- クエリ用のAPI
- 高可用性:サービスディスカバリシステムはシステム全体の神経であり、麻痺やクラッシュが許されません
- エコシステム:プログラマーは怠け者であり、APIと簡単にやり取りできるライブラリを好むため
市場で主流のオープンソースサービスディスカバリシステムをいくつか見てみましょう:
Consul
Consulは、主要なオープンソース企業であるHashicorpが開発したサービスディスカバリシステムです。2014年4月17日に最初のバージョンをリリースした老舗のソフトウェアであり、Consulは最も豊富なエコシステムの1つを持ち、HaskellのSDKを開発するサードパーティ開発者さえいます。ConsulのSDKのほとんどは、そのHTTP APIのラッパーに過ぎないため、開発作業はそれほど多くありません。
Consulは、HTTP APIを介したサービスの登録とクエリをサポートしています。クエリ時にデータをタイムリーにプッシュするためにHTTPロングポーリングをサポートしており、ポーリングを回避します。また、ConsulはDNSを介して対応するサービスのインスタンスをクエリすることもサポートしています。
Consulのデプロイメントは興味深く、各Consulインスタンスはエージェントと呼ばれ、クライアントまたはサーバーのいずれかになります。クライアント側では、Consulはクライアント側の状態を維持します。サーバー側では、Consulは一貫性アルゴリズムRaftを介した分散デプロイメントをサポートし、高可用性を実現します。
Eureka
EurekaはNetflixがオープンソース化したプロジェクトで、かなり古いものです(2012年までのコミットの痕跡があります)。しかし、このプロジェクトは1年間メンテナンスされていません。多くのユーザーは、後述するNacosに移行しています。
Eurekaは、HTTP APIとJava SDKを介したインタラクションをサポートしています。Eurekaの多くのユーザーは、実際にはSpring CloudなどのJavaエコシステムのプロジェクトを通じて導入されました。Eurekaの高可用性設計は、CAP定理(分散システムは一貫性、可用性、パーティション耐性の3つのプロパティのうち2つしか同時に提供できないと述べています)で言えばAPであり、ネットワークが分断された場合にクライアントが期限切れのデータを見ることができるため、ネットワーク問題による二次災害を回避します。
Nacos
Nacosは、Alibabaが開発したサービスディスカバリシステムで、その名前はNamingとConfiguration Serviceの最初の数文字を組み合わせたものです。2018年7月20日にバージョン0.1.0をリリースして以来、Nacosは現在バージョン2.1に進化しています。
Alibabaの多くのオープンソースプロジェクトと同様に、Nacosは中国のJava開発者の間で非常に人気があり、その人気はEurekaよりもかなり高いです。
Nacosは、HTTP APIおよびJava/Go/Python/NodeJS/C#などのSDKを介したサービスの登録とクエリをサポートしています。現在、Nacosの開発者はgRPCに基づく新しいAPIにも取り組んでいます。HTTP APIの場合、Nacosは現在サービスのリストをポーリングすることしかサポートしていません。そのため、Nacosは公式にはSDKアプローチを好んでおり、これはポーリング+UDPベースのプッシュアプローチで、リアルタイム性が優れています。Nacosはまた、gRPCに基づく新しいAPIにも取り組んでおり、サーバーサイドプッシュ機能を導入します。これは、SDKにアクセスできないシステムにとって大きな利点です。
Nacosの高可用性は、クライアントSDKに提供される永続性機能と、サーバー側の一貫性をRaftおよびDistroプロトコルで実現していることに一部起因しています。
一般的なインターフェース方法とその利点と欠点
プライベートプロトコルを除いて、サービスディスカバリのインターフェース方法は3つに分類できます:
- HTTPポーリング
- DNS
- HTTPロングポーリングまたはgRPCサーバーストリーミング
HTTPポーリングは実装が簡単ですが、リアルタイム性がありません。
DNSのパフォーマンスオーバーヘッドは最小限です。DNSキャッシュのため、DNSもリアルタイムではありませんが、広く受け入れられており、実装に依存しない標準セットであるという利点があります。しかし、これは両刃の剣でもあり、サービスディスカバリシステムがDNSレスポンスに追加のフィールドを追加できないことを意味します。DNSレスポンスのAdditionalフィールドを使用する場合を除きますが、これにはクライアント側での特別な処理が必要です。
HTTPロングポーリングまたはgRPCサーバーストリーミングは、3つの中で最もリアルタイム性があります。どちらもHTTPベースであるため、レスポンスを簡単にカスタマイズできます。欠点は、クライアント側での実装が比較的難しいことです。
APISIXがサービスディスカバリシステムとインターフェースする方法
クラウドネイティブゲートウェイとして、APISIXはサービスディスカバリシステムからアップストリームノードを取得することをサポートしており、データプレーンとコントロールプレーンの両方でサービスディスカバリシステムとのインターフェースをサポートするように設計されています。
データプレーン
APISIXは、データプレーンでDNS、Eureka、Consul(KVモード)、Nacos、K8sとの統合をサポートしています。
DNSサービスとインターフェースする場合、APISIXはDNSのSRVまたはA/AAAAレコードを使用して、サービスの特定のアップストリームノードを取得します。アップストリームにアクセスするリクエストが行われると、まずDNSキャッシュから取得しようとします。ない場合、DNSクエリを開始して、対応するレコード内の特定のIPアドレスを取得します。
他のサービスディスカバリタイプについては、バックグラウンドで同期されます。アップストリームにアクセスするリクエストが行われると、現在同期されているデータからサービス名に対応する部分のデータが取得されます。K8sとConsul KVの場合、HTTPロングポーリングをサポートしているため、この方法で変更されたIPアドレスをリアルタイムで取得できます。EurekaとNacosについては、現在はデータをポーリングしているだけです。
コントロールプレーン
APISIXは、コントロールプレーンでのサービスディスカバリもサポートしています。apisix-seedに取り組んでおり、サービスディスカバリシステムからetcdにデータを同期させ、データプレーンがetcdから最新のアップストリームノードを同期できるようにします。
現在、コントロールプレーンでNacosとZookeeperのサポートを実装しています。コントロールプレーンでのサービスディスカバリサポートは公式SDKを介して実装されているため、通常のHTTP方法では得られない利点があります。例えば、Nacosのapisix-seed実装では、UDPベースのプッシュをサポートしているため、HTTPポーリングよりもデータの時間効率が優れています。
APISIXがサービスディスカバリシナリオをサポートする利点
ゲートウェイに直接サービスディスカバリを統合することで、サービスをオンラインにする作業を大幅に簡素化できます。APISIXをサービスディスカバリシステムとインターフェースするように設定し、残りはAPISIXに任せます。 例えば、会社がNacosをサービスディスカバリシステムとして使用している場合、APISIXを設定してNacosサービスディスカバリを有効にし、APISIXのアップストリームにサービス名を設定するだけで、APISIXが自動的にそのアップストリームに対応する特定のIPノードを取得します。
これは、ゲートウェイを移行する際に必要な作業量を大幅に削減できる利点です。例えば、Spring Cloud GatewayからAPISIXに移行する場合、Spring Cloud GatewayがEurekaまたはNacosをサービスディスカバリに使用している場合、APISIX内でEurekaまたはNacosのサポートを有効にするだけで、新しいシステムへの移行が可能です。
Huan Bei Loanはこの分野で豊富な経験を持ち、Spring Cloud Gatewayの置き換えは、安定性、監視、精度、および有効性をさらに向上させることを目的としています。
Huan Bei Loanの原文を引用すると:
ビジネスとして、コストは依然として考慮すべき原則です。急成長期には、ビジネスの成長をできるだけ早く促進する必要があるかもしれません。しかし、現在の環境では、予算内のコストが優先されます。この場合、効率とコストはどちらか一方しか維持できません。そのため、限られたコストの中で、企業は技術の進歩についてあまり話さなくなります。選択プロセスでは、技術スタッフは選択した技術がチームにどれだけの影響を与えるか、既存の運用とアーキテクチャにどれだけの利益をもたらすかなどをあまり考慮せず、コストの観点からより多くを考慮します。
さらに、APISIXは複数のサービスディスカバリの同時設定をサポートしています。歴史的な理由から、多くの企業は複数のサービスディスカバリシステムを持っている可能性があります。例えば、私が知る限り、一部の企業は古いEurekaサービスディスカバリと新しいNacosサービスディスカバリの両方を持っています。APISIXは、EurekaとNacosの両方を有効にするだけで、この状況に対応できます。
現在APISIXで直接アップストリームノードを設定している場合、別のサービスディスカバリシステムをデプロイし、サービスディスカバリシステムに特定のノード設定を保存することを検討することもできます。アップストリームノード設定をAPISIXから専用のサービスディスカバリシステムに移行する利点は、クライアントがサービス登録を自分で行えることと、専用のサービスディスカバリシステムがより豊富なヘルスチェックなどの追加機能を提供することが多いことです。
将来的には、APISIX Ingress Controllerでさまざまなサービス登録およびディスカバリコンポーネントの統合をサポートし、ユーザーがより簡単に使用できるようにする予定です。その時、ユーザーはAPISIX Ingress ControllerでK8sサービスのエンドポイントをアップストリームノードとして指定できるだけでなく、サービスディスカバリによって取得されたノードを統合することもできるようになります。