Parte 2: Cómo construir una API gateway para microservicios usando OpenResty
API7.ai
February 2, 2023
Después de comprender los componentes principales y las abstracciones de una puerta de enlace de API de microservicios, es hora de comenzar e implementar la selección técnica. Hoy, veremos la selección técnica de los cuatro componentes principales respectivamente: almacenamiento, enrutamiento, esquema y plugins.
Almacenamiento
Como se mencionó en el artículo anterior, el almacenamiento es un componente básico muy crítico en la base, que afectará a problemas centrales como cómo sincronizar la configuración, cómo escalar el clúster y cómo garantizar la alta disponibilidad, por lo que lo colocamos al principio del proceso de selección.
Veamos dónde almacenan sus datos las puertas de enlace de API existentes: Kong en PostgreSQL o Cassandra. Y Orange, también basado en OpenResty, en MySQL. Sin embargo, estas opciones tienen muchos inconvenientes.
Primero, el almacenamiento debe ser una solución de alta disponibilidad separada. Las bases de datos PostgreSQL y MySQL tienen su propia solución de alta disponibilidad. Aún así, también necesitarás un DBA y recursos de máquina, y es difícil hacer un cambio rápido en caso de fallo.
Segundo, solo podemos sondear la base de datos para obtener cambios de configuración y no podemos hacer un "push". Esto aumentará el consumo de recursos de la base de datos y reducirá la capacidad de respuesta en tiempo real de los cambios.
Tercero, debes mantener tus versiones históricas y considerar reversiones y actualizaciones. Por ejemplo, si un usuario publica un cambio, puede haber operaciones de reversión posteriores, en cuyo punto necesitas hacer tu diff entre las dos versiones a nivel de código para la reversión de la configuración. Además, cuando el sistema se actualiza, puede modificar la estructura de la tabla de la base de datos, por lo que el código debe considerar la compatibilidad de las versiones antiguas y nuevas y las actualizaciones de datos.
Cuarto, aumenta la complejidad del código. Además de implementar la funcionalidad de la puerta de enlace, necesitas parchear los primeros tres defectos del código, lo que obviamente hace que el código sea mucho menos legible.
Quinto, aumenta la dificultad de implementación, operación y mantenimiento. Implementar y mantener una base de datos relacional no es una tarea simple, y es aún más complicado si es un clúster de bases de datos. No podemos hacer un escalado rápido.
¿Cómo deberíamos elegir para estos casos?
Volvamos a los requisitos originales de la puerta de enlace de API, donde se almacena información de configuración simple, como URI, parámetros de plugins, direcciones de upstream, etc. No se involucran operaciones complejas de unión, y no se requieren garantías estrictas de transacción. En este caso, usar una base de datos relacional no es "matar una mosca a cañonazos", ¿verdad?
De hecho, minimizar el uso de K8s y mantenerlo más cerca, etcd, es la elección correcta.
- El número de cambios por segundo en los datos de configuración de la puerta de enlace de API no es grande, lo que permite un rendimiento suficiente para etcd.
- La agrupación en clúster y el escalado dinámico son ventajas inherentes de etcd.
- etcd también tiene una interfaz
watch, por lo que no tienes que sondear para obtener cambios.
Otra cosa que prueba la confiabilidad de etcd es que ya es la elección predeterminada para guardar configuraciones en el sistema K8s y ha sido validado para muchos escenarios más complejos que las puertas de enlace de API.
Enrutamiento
El enrutamiento también es una selección técnica esencial, y todas las solicitudes son filtradas por la ruta a la lista de plugins que necesitan ser cargados, ejecutados uno por uno, y luego reenviados al upstream especificado. Sin embargo, considerando que puede haber más reglas de enrutamiento, necesitamos enfocarnos en la complejidad temporal del algoritmo para la selección técnica de enrutamiento aquí.
Comencemos por ver qué rutas están disponibles bajo OpenResty. Luego, como de costumbre, busquemos cada una de ellas en el proyecto awesome-resty, que tiene bibliotecas de enrutamiento especiales:
• lua-resty-route — Una biblioteca de enrutamiento de URL para OpenResty que admite múltiples comparadores de rutas, middleware y manejadores HTTP y WebSockets, por mencionar algunas de sus características • router.lua — Un enrutador básico para Lua, coincide con URLs y ejecuta funciones Lua • lua-resty-r3 — Implementación de libr3 para OpenResty, libr3 es una biblioteca de despacho de rutas de alto rendimiento. Compila tus rutas en un árbol de prefijos (trie). Al usar el trie de prefijos construido en el tiempo de inicio, puedes despachar tus rutas con eficiencia • lua-resty-libr3 — Biblioteca de despacho de rutas de alto rendimiento basada en libr3 para OpenResty
Como puedes ver, esto contiene las implementaciones de las cuatro bibliotecas de enrutamiento. Desafortunadamente, los primeros dos enrutamientos son implementaciones puras de Lua, que son relativamente simples, por lo que hay varias características faltantes que aún no cumplen con los requisitos de generación.
Las dos últimas bibliotecas en realidad están basadas en la biblioteca C libr3 con una capa de envoltura usando FFI, mientras que libr3 en sí usa un árbol de prefijos. Este algoritmo no tiene nada que ver con el número N de reglas almacenadas, sino solo con la longitud K de los datos de coincidencia, por lo que la complejidad temporal es O(K).
Sin embargo, libr3 tiene sus desventajas. Sus reglas de coincidencia difieren de las del familiar NGINX location, y no admite devoluciones de llamada. Esto nos deja sin forma de establecer las condiciones para el enrutamiento basado en encabezados de solicitud, cookies y variables de NGINX, lo que obviamente no es lo suficientemente flexible para los escenarios de puerta de enlace de API.
Sin embargo, aunque nuestros intentos de encontrar una biblioteca de enrutamiento utilizable en awesome-resty no tuvieron éxito, la implementación de libr3 nos señala una nueva dirección: implementar árboles de prefijos y envolturas FFI en C, lo que debería acercarse a la solución óptima en términos de complejidad temporal y rendimiento del código.
Casualmente, los autores de Redis han abierto el código de una implementación en C del árbol radix, que es un árbol de prefijos comprimido. Siguiendo la pista, también podemos encontrar la biblioteca de envoltura FFI para rax disponible en OpenResty, que tiene el siguiente código de ejemplo:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
Como puedes ver, lua-resty-radixtree admite múltiples dimensiones para la búsqueda de rutas basadas en URI, host, método HTTP, encabezado HTTP, variables de NGINX, dirección IP, etc. Además, la complejidad temporal del árbol base es O(K), que es mucho más eficiente que el enfoque comúnmente utilizado de recorrido + caché hash.
Esquema
Elegir el esquema es mucho más fácil. El lua-rapidjson que presentamos anteriormente es una muy buena opción. No necesitas escribir uno para esta parte; el esquema JSON es lo suficientemente poderoso. El siguiente es un ejemplo simple.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Plugin
Con la base anterior de almacenamiento, enrutamiento y esquema, es mucho más evidente cómo debería implementarse la capa superior de plugins. No hay bibliotecas de código abierto listas para usar en plugins. Necesitamos implementarlos nosotros mismos. Al diseñar plugins, hay tres aspectos principales que debemos considerar claramente.
Lo primero es cómo montarlo. Queremos que el plugin se monte en las fases de rewrite, access, header filter, body filter y log, e incluso que configure su algoritmo de balanceo de carga en la etapa de balancer. Por lo tanto, deberíamos exponer estas etapas en el archivo de configuración de NGINX y dejar la interfaz abierta en la implementación del plugin.
Lo siguiente es cómo obtener los cambios de configuración. Dado que no hay restricciones de base de datos relacional, los cambios en los parámetros del plugin se pueden implementar a través del watch de etcd, lo que hace que la lógica del código del marco general sea mucho más transparente y fácil de entender.
Finalmente, necesitamos considerar la prioridad de los plugins. Por ejemplo, ¿qué plugin debería ejecutarse primero? ¿para autenticación o para limitar el flujo y la velocidad? Cuando hay una condición de carrera entre un plugin vinculado a la ruta y otro plugin vinculado al servicio, ¿cuál debería tener prioridad? Estas son todas cosas que debemos considerar en su lugar.
Después de ordenar estos tres problemas del plugin, podemos obtener un diagrama de flujo del funcionamiento interno del plugin:
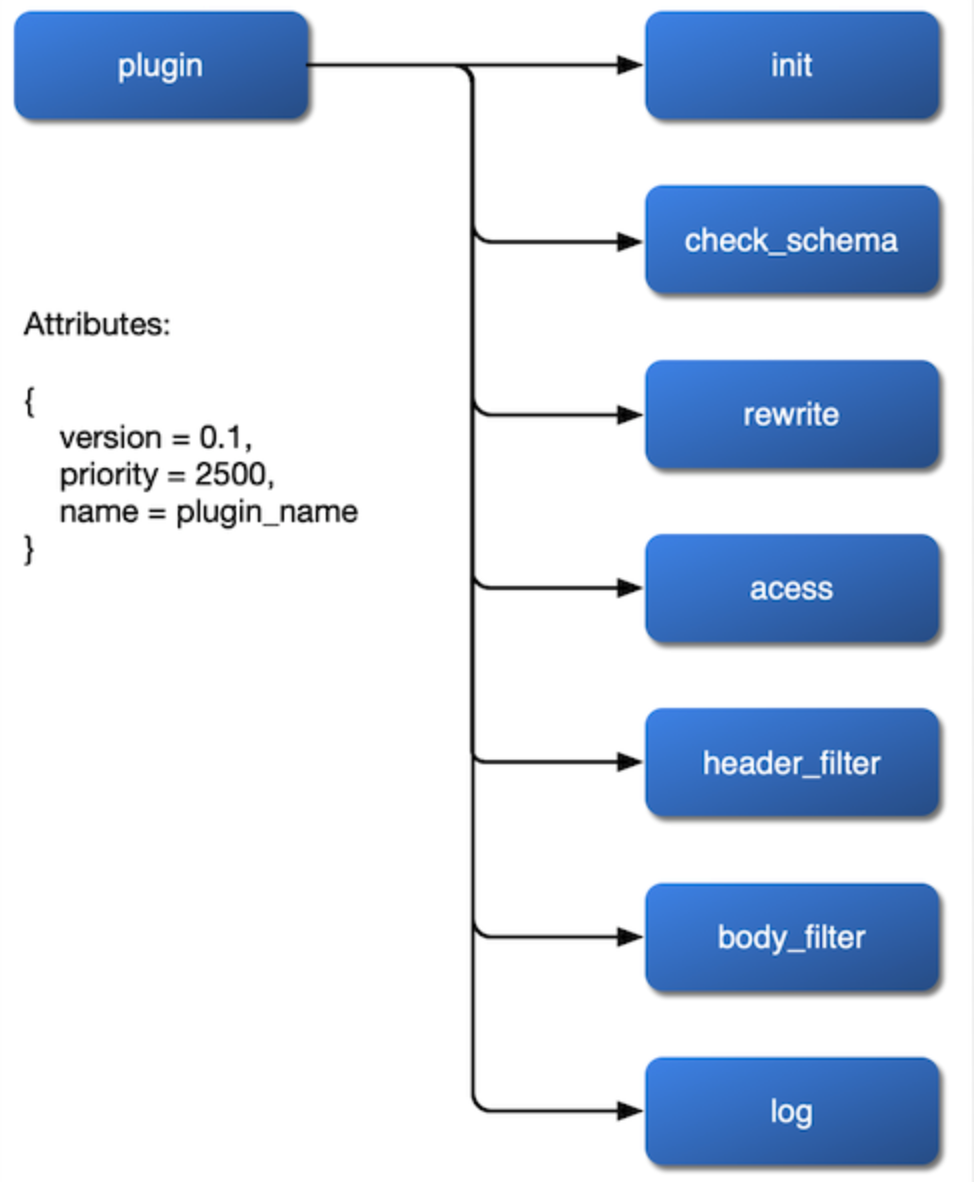{kind=link}
Infraestructura
Naturalmente, cuando estos componentes críticos de la puerta de enlace de API de microservicios están determinados, el flujo de procesamiento de las solicitudes de los usuarios se establecerá. Aquí dibujo un diagrama para mostrar este proceso:
Diagrama del flujo de procesamiento de solicitudes de usuarios
{kind=link}
En esta figura, podemos ver que cuando una solicitud de usuario entra en la puerta de enlace de API,
- En primer lugar, las reglas de enrutamiento se compararán según los métodos de solicitud, URI, host y condiciones del encabezado de solicitud. Si se acierta en una regla de enrutamiento, se obtendrá la lista de plugins correspondiente de etcd.
- Luego, se intersecta con la lista de plugins abiertos localmente para obtener la lista final de plugins que se pueden ejecutar.
- Y luego se ejecutan los plugins uno por uno según su prioridad.
- Finalmente, la solicitud se envía al upstream según la verificación de salud del upstream y el algoritmo de balanceo de carga.
Estaremos listos para escribir código específico cuando se complete el diseño de la arquitectura. Esto es en realidad como construir una casa. Solo después de tener el plano y la base sólida puedes hacer el trabajo concreto de construir ladrillos y tejas.
Resumen
De hecho, a través del estudio de estos dos artículos, hemos hecho las dos cosas más importantes de posicionamiento del producto y selección de tecnología, que son más críticas que la implementación específica de codificación. Por favor, considera y elige con más cuidado.
Entonces, ¿has usado alguna vez una puerta de enlace de API en tu trabajo real? ¿Cómo elige tu empresa la puerta de enlace de API? Bienvenido a dejar un mensaje y compartir tu experiencia y ganancias conmigo. También te invitamos a compartir este artículo con más personas para que puedas comunicarte y progresar.
Anterior: Parte 1: Cómo construir una puerta de enlace de API de microservicios usando OpenResty Siguiente: Parte 3: Cómo construir una puerta de enlace de API de microservicios usando OpenResty