Parte 2: Como construir um gateway de API para Microservices usando OpenResty
API7.ai
February 2, 2023
Após entender os componentes principais e as abstrações de um gateway de API de microsserviços, é hora de começar e implementar a seleção técnica. Hoje, vamos analisar a seleção técnica dos quatro componentes principais: armazenamento, roteamento, esquema e plugins.
Armazenamento
Como mencionado no artigo anterior, o armazenamento é um componente básico muito crítico na base, que afetará questões centrais como como sincronizar a configuração, como escalar o cluster e como garantir alta disponibilidade, por isso o colocamos no início do processo de seleção.
Vamos dar uma olhada em onde os gateways de API existentes armazenam seus dados: Kong no PostgreSQL ou Cassandra. E Orange, também baseado no OpenResty, no MySQL. No entanto, essas opções têm muitas desvantagens.
Primeiro, o armazenamento precisa ser uma solução separada de alta disponibilidade. Os bancos de dados PostgreSQL e MySQL têm suas próprias soluções de alta disponibilidade. Ainda assim, você também precisará de DBA e recursos de máquina, e é difícil fazer uma troca rápida em caso de falha.
Segundo, só podemos consultar o banco de dados para obter alterações de configuração e não podemos fazer push. Novamente, isso aumentará o consumo de recursos do banco de dados e reduzirá a eficiência em tempo real das alterações.
Terceiro, você deve manter suas versões históricas e considerar rollbacks e upgrades. Por exemplo, se um usuário liberar uma alteração, pode haver operações de rollback subsequentes, momento em que você precisará fazer o diff entre as duas versões no nível do código para o rollback da configuração. Além disso, quando o sistema é atualizado, ele pode modificar a estrutura da tabela do banco de dados, então o código deve considerar a compatibilidade das versões antigas e novas e as atualizações de dados.
Quarto, aumenta a complexidade do código. Além de implementar a funcionalidade do gateway, você precisa corrigir os três primeiros defeitos do código, o que obviamente torna o código muito menos legível.
Quinto, aumenta a dificuldade de implantação, operação e manutenção. Implantar e manter um banco de dados relacional não é uma tarefa simples, e é ainda mais complicado se for um cluster de banco de dados. Não podemos fazer escalonamento rápido.
Como devemos escolher para esses casos?
Vamos voltar aos requisitos originais do gateway de API, onde informações simples de configuração são armazenadas, como URI, parâmetros de plugin, endereços upstream, etc. Nenhuma operação complexa de join é envolvida, e nenhuma garantia de transação estrita é necessária. Nesse caso, usar um banco de dados relacional não é "matar a galinha com uma faca de abate", certo?
Na verdade, minimizar o uso do K8s e manter mais próximo, etcd, é a escolha certa.
- O número de alterações por segundo nos dados de configuração do gateway de API não é grande, o que permite desempenho suficiente para o etcd.
- Clusterização e escalonamento dinâmico são vantagens inerentes do etcd.
- O etcd também tem uma interface
watch, então você não precisa consultar para obter alterações.
Outra coisa que prova a confiabilidade do etcd é que ele já é a escolha padrão para salvar configurações no sistema K8s e foi validado para muitos cenários mais complexos do que gateways de API.
Roteamento
O roteamento também é uma seleção técnica essencial, e todas as solicitações são filtradas pela rota para a lista de plugins que precisam ser carregados, executados um por um e, em seguida, encaminhados para o upstream especificado. No entanto, considerando que pode haver mais regras de roteamento, precisamos nos concentrar na complexidade de tempo do algoritmo para a seleção técnica de roteamento aqui.
Vamos começar olhando para as rotas disponíveis no OpenResty. Então, como de costume, vamos procurar cada uma delas no projeto awesome-resty, que tem bibliotecas de roteamento especiais:
• lua-resty-route — Uma biblioteca de roteamento de URL para OpenResty suportando múltiplos matchers de rota, middleware e handlers HTTP e WebSockets, para mencionar algumas de suas características • router.lua — Um roteador básico para Lua, ele corresponde URLs e executa funções Lua • lua-resty-r3 — Implementação do libr3 para OpenResty, libr3 é uma biblioteca de despacho de caminho de alta performance. Ele compila seus caminhos de rota em uma árvore de prefixo (trie). Usando a árvore de prefixo construída no tempo de inicialização, você pode despachar suas rotas com eficiência • lua-resty-libr3 — Biblioteca de despacho de caminho de alta performance baseada no libr3 para OpenResty
Como você pode ver, isso contém as implementações das quatro bibliotecas de roteamento. Infelizmente, os dois primeiros roteamentos são implementações puras em Lua, que são relativamente simples, então há várias funcionalidades ausentes que ainda não atendem aos requisitos de geração.
As duas últimas bibliotecas são, na verdade, baseadas na biblioteca C libr3 com uma camada de encapsulamento usando FFI, enquanto o libr3 em si usa uma árvore de prefixo. Esse algoritmo não tem nada a ver com o número N de regras armazenadas, mas apenas com o comprimento K dos dados correspondentes, então a complexidade de tempo é O(K).
No entanto, o libr3 tem suas desvantagens. Suas regras de correspondência diferem das do familiar NGINX location, e ele não suporta callbacks. Isso nos deixa sem uma maneira de definir as condições de roteamento com base em cabeçalhos de solicitação, cookies e variáveis NGINX, o que obviamente não é flexível o suficiente para cenários de gateway de API.
No entanto, embora nossas tentativas de encontrar uma biblioteca de roteamento utilizável no awesome-resty tenham sido infrutíferas, a implementação do libr3 nos aponta uma nova direção: implementar árvores de prefixo e encapsulamentos FFI em C, o que deve se aproximar da solução ideal em termos de complexidade de tempo e desempenho de código.
Por coincidência, os autores do Redis abriram o código de uma implementação em C da árvore radix, que é uma árvore de prefixo compactada. Seguindo a trilha, também podemos encontrar a biblioteca de encapsulamento FFI para rax disponível no OpenResty, que tem o seguinte código de exemplo:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
Como você pode ver, o lua-resty-radixtree suporta múltiplas dimensões para pesquisa de rota com base em URI, host, método HTTP, cabeçalho HTTP, variáveis NGINX, endereço IP, etc. Além disso, a complexidade de tempo da árvore base é O(K), o que é muito mais eficiente do que a abordagem comumente usada de traversal + cache hash.
Esquema
Escolher o esquema é muito mais fácil. O lua-rapidjson que apresentamos anteriormente é uma escolha muito boa. Você não precisa escrever um para esta parte; o esquema JSON é poderoso o suficiente. Aqui está um exemplo simples.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Plugin
Com a base acima de armazenamento, roteamento e esquema, fica muito mais claro como a camada superior de plugins deve ser implementada. Não há bibliotecas de código aberto prontas para usar em plugins. Precisamos implementá-los nós mesmos. Ao projetar plugins, há três aspectos principais que precisamos considerar claramente.
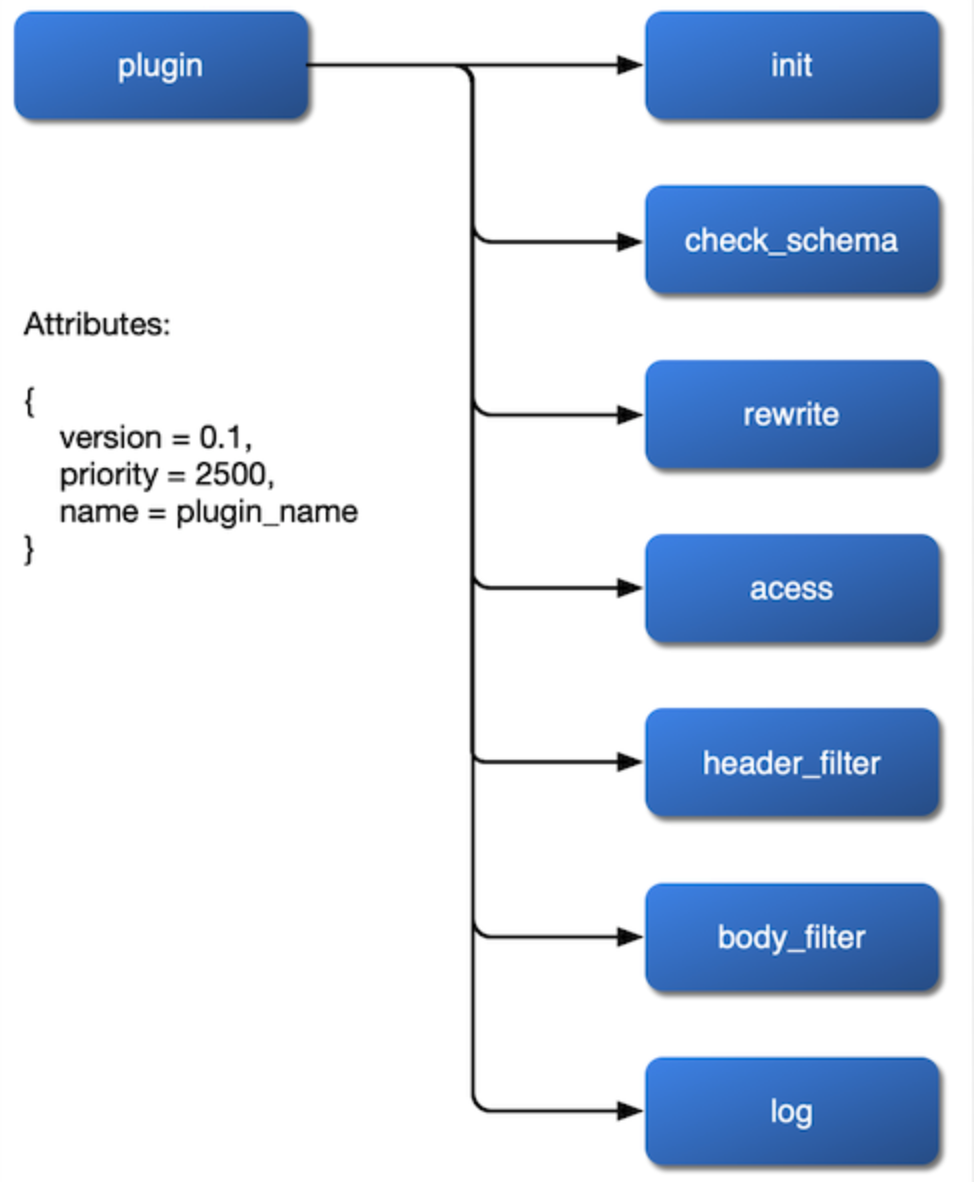
A primeira coisa é como montá-lo. Queremos que o plugin seja montado nas fases de rewrite, access, header filter, body filter e log, e até mesmo configurar seu algoritmo de balanceamento de carga na fase de balancer. Então, devemos expor essas fases no arquivo de configuração do NGINX e deixar a interface aberta na implementação do plugin.
O próximo é como obter as alterações de configuração. Como não há restrições de banco de dados relacional, as alterações nos parâmetros do plugin podem ser implementadas através do watch do etcd, o que torna a lógica do código do framework geral muito mais transparente e fácil de entender.
Finalmente, precisamos considerar a prioridade dos plugins. Por exemplo, qual plugin deve ser executado primeiro? para autenticação ou limitação de fluxo e velocidade? Quando há uma condição de corrida entre um plugin vinculado à rota e outro plugin vinculado ao serviço, qual deve ter precedência? Essas são todas coisas que precisamos considerar no lugar.
Após resolver essas três questões do plugin, podemos obter um fluxograma do funcionamento interno do plugin:
{kind=link}
Infraestrutura
Naturalmente, quando esses componentes críticos do gateway de API de microsserviços são determinados, o fluxo de processamento de solicitações do usuário será definido. Aqui eu desenhei um diagrama para mostrar esse processo:
Diagrama do fluxo de processamento de solicitações do usuário
{kind=link}
A partir desta figura, podemos ver que quando uma solicitação do usuário entra no gateway de API,
- Primeiro, as regras de roteamento serão correspondidas de acordo com os métodos de solicitação, URI, host e condições de cabeçalho de solicitação. Se você acertar uma regra de roteamento, obterá a lista de plugins correspondente do etcd.
- Em seguida, ele cruza com a lista de plugins abertos localmente para obter a lista final de plugins que podem ser executados.
- E então executa os plugins um por um de acordo com sua prioridade.
- Finalmente, a solicitação é enviada para o upstream de acordo com a verificação de saúde do upstream e o algoritmo de balanceamento de carga.
Estaremos prontos para escrever código específico quando o design da arquitetura for concluído. Isso é realmente como construir uma casa. Somente depois de ter o projeto e a base sólida você pode fazer o trabalho concreto de construir tijolos e telhas.
Resumo
Na verdade, através do estudo desses dois artigos, fizemos as duas coisas mais importantes de posicionamento de produto e seleção de tecnologia, que são mais críticas do que a implementação de codificação específica. Por favor, considere e escolha com mais cuidado.
Então, você já usou gateway de API em seu trabalho real? Como sua empresa escolhe o gateway de API? Sinta-se à vontade para deixar uma mensagem e compartilhar sua experiência e ganhos comigo. Você também é bem-vindo a compartilhar este artigo com mais pessoas para que você possa se comunicar e progredir.
Anterior: Parte 1: Como construir um gateway de API de microsserviços usando OpenResty Próximo: Parte 3: Como construir um gateway de API de microsserviços usando OpenResty