Partie 2 : Comment construire une passerelle API Microservices avec OpenResty
API7.ai
February 2, 2023
Après avoir compris les composants de base et les abstractions d'une passerelle API de microservices, il est temps de commencer et de mettre en œuvre la sélection technique. Aujourd'hui, nous allons examiner la sélection technique des quatre composants de base respectivement : le stockage, le routage, le schéma et les plugins.
Stockage
Comme mentionné dans l'article précédent, le stockage est un composant de base très critique au niveau inférieur, qui affectera les problèmes fondamentaux tels que la synchronisation de la configuration, la mise à l'échelle du cluster et la garantie de haute disponibilité. C'est pourquoi nous le plaçons au tout début du processus de sélection.
Examinons où les passerelles API existantes stockent leurs données : Kong utilise PostgreSQL ou Cassandra. Et Orange, également basé sur OpenResty, utilise MySQL. Cependant, ces options présentent de nombreux inconvénients.
Premièrement, le stockage doit être une solution de haute disponibilité distincte. Les bases de données PostgreSQL et MySQL ont leurs propres solutions de haute disponibilité. Cependant, vous aurez également besoin d'un DBA et de ressources machines, et il est difficile de faire un basculement rapide en cas de défaillance.
Deuxièmement, nous ne pouvons que interroger la base de données pour obtenir les changements de configuration et ne pouvons pas faire de notifications en temps réel. Cela augmente la consommation des ressources de la base de données et réduit la réactivité des changements.
Troisièmement, vous devez maintenir vos versions historiques et envisager les retours en arrière et les mises à niveau. Par exemple, si un utilisateur publie un changement, il peut y avoir des opérations de retour en arrière ultérieures, auquel cas vous devez faire votre diff entre les deux versions au niveau du code pour le retour en arrière de la configuration. De plus, lorsque le système est mis à niveau, il peut modifier la structure de la table de la base de données, donc le code doit prendre en compte la compatibilité des anciennes et nouvelles versions ainsi que les mises à niveau des données.
Quatrièmement, cela augmente la complexité du code. En plus de mettre en œuvre la fonctionnalité de la passerelle, vous devez corriger les trois premiers défauts du code, ce qui rend évidemment le code beaucoup moins lisible.
Cinquièmement, cela augmente la difficulté de déploiement, d'exploitation et de maintenance. Déployer et maintenir une base de données relationnelle n'est pas une tâche simple, et c'est encore plus compliqué s'il s'agit d'un cluster de bases de données. Nous ne pouvons pas faire de mise à l'échelle rapide.
Comment devrions-nous choisir pour ces cas ?
Revenons aux exigences originales de la passerelle API, où des informations de configuration simples sont stockées, telles que l'URI, les paramètres des plugins, les adresses en amont, etc. Aucune opération de jointure complexe n'est impliquée, et aucune garantie de transaction stricte n'est requise. Dans ce cas, utiliser une base de données relationnelle n'est pas "tuer une mouche avec un marteau", n'est-ce pas ?
En fait, minimiser l'utilisation de K8s et se rapprocher de etcd est le bon choix.
- Le nombre de changements par seconde dans les données de configuration de la passerelle API n'est pas élevé, ce qui permet à etcd d'offrir des performances suffisantes.
- Le clustering et la mise à l'échelle dynamique sont des avantages inhérents à etcd.
- etcd dispose également d'une interface
watch, donc vous n'avez pas besoin d'interroger pour obtenir les changements.
Une autre chose qui prouve la fiabilité de etcd est qu'il est déjà le choix par défaut pour sauvegarder les configurations dans le système K8s et a été validé pour des scénarios beaucoup plus complexes que les passerelles API.
Routage
Le routage est également une sélection technique essentielle, et toutes les demandes sont filtrées par la route vers la liste des plugins qui doivent être chargés, exécutés un par un, puis transférés vers l'amont spécifié. Cependant, étant donné qu'il peut y avoir plus de règles de routage, nous devons nous concentrer sur la complexité temporelle de l'algorithme pour la sélection technique du routage ici.
Commençons par examiner quelles routes sont disponibles sous OpenResty. Ensuite, comme d'habitude, examinons chacune d'elles dans le projet awesome-resty, qui a des bibliothèques de routage spéciales :
• lua-resty-route — Une bibliothèque de routage d'URL pour OpenResty prenant en charge plusieurs matchers de route, middleware et gestionnaires HTTP et WebSockets pour mentionner quelques-unes de ses fonctionnalités • router.lua — Un routeur minimaliste pour Lua, il correspond aux URL et exécute des fonctions Lua • lua-resty-r3 — Implémentation OpenResty de libr3, libr3 est une bibliothèque de dispatch de chemin haute performance. Il compile vos chemins de route en un arbre de préfixes (trie). En utilisant l'arbre de préfixes construit au démarrage, vous pouvez dispatcher vos routes avec efficacité • lua-resty-libr3 — Bibliothèque de dispatch de chemin haute performance basée sur libr3 pour OpenResty
Comme vous pouvez le voir, cela contient les implémentations des quatre bibliothèques de routage. Malheureusement, les deux premières routages sont des implémentations purement Lua, qui sont relativement simples, donc il manque pas mal de fonctionnalités qui ne répondent pas encore aux exigences de génération.
Les deux dernières bibliothèques sont en fait basées sur la bibliothèque C libr3 avec une couche d'emballage utilisant FFI, tandis que libr3 lui-même utilise un arbre de préfixes. Cet algorithme n'a rien à voir avec le nombre N de règles stockées mais seulement avec la longueur K des données correspondantes, donc la complexité temporelle est O(K).
Cependant, libr3 a ses inconvénients. Ses règles de correspondance diffèrent de celles du location NGINX familier, et il ne prend pas en charge les callbacks. Cela nous laisse sans moyen de définir les conditions de routage basées sur les en-têtes de requête, les cookies et les variables NGINX, ce qui n'est manifestement pas assez flexible pour les scénarios de passerelle API.
Cependant, bien que nos tentatives pour trouver une bibliothèque de routage utilisable dans awesome-resty aient échoué, l'implémentation de libr3 nous oriente dans une nouvelle direction : implémenter des arbres de préfixes et des emballages FFI en C, ce qui devrait se rapprocher de la solution optimale en termes de complexité temporelle et de performance du code.
Il se trouve que les auteurs de Redis ont open-sourcé une implémentation C de l'arbre radix, qui est un arbre de préfixes compressé. En suivant la piste, nous pouvons également trouver la bibliothèque d'emballage FFI pour rax disponible dans OpenResty, qui a le code d'exemple suivant :
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
Comme vous pouvez le voir, lua-resty-radixtree prend en charge plusieurs dimensions pour la recherche de route basée sur l'URI, l'hôte, la méthode HTTP, l'en-tête HTTP, les variables NGINX, l'adresse IP, etc. De plus, la complexité temporelle de l'arbre de base est O(K), ce qui est beaucoup plus efficace que l'approche couramment utilisée de traversal + cache de hachage.
Schéma
Choisir un schéma est beaucoup plus facile. Le lua-rapidjson que nous avons présenté précédemment est un très bon choix. Vous n'avez pas besoin d'en écrire un pour cette partie ; le schéma JSON est suffisamment puissant. Voici un exemple simple.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Plugin
Avec les bases ci-dessus de stockage, routage et schéma, il est beaucoup plus évident de savoir comment la couche supérieure des plugins devrait être implémentée. Il n'y a pas de bibliothèques open-source prêtes à l'emploi pour les plugins. Nous devons les implémenter nous-mêmes. Lors de la conception des plugins, il y a trois aspects principaux que nous devons considérer clairement.
La première chose est comment le monter. Nous voulons que le plugin soit monté sur les phases rewrite, access, header filer, body filter et log, et même qu'il configure son algorithme de répartition de charge dans la phase balancer. Nous devrions donc exposer ces phases dans le fichier de configuration NGINX et laisser l'interface ouverte dans l'implémentation du plugin.
Ensuite, comment obtenir les changements de configuration. Comme il n'y a pas de contraintes de base de données relationnelles, les changements de paramètres de plugin peuvent être implémentés via le watch de etcd, ce qui rend la logique globale du code du cadre beaucoup plus transparente et plus facile à comprendre.
Enfin, nous devons considérer la priorité des plugins. Par exemple, quel plugin doit être exécuté en premier ? pour l'authentification ou la limitation de débit et de vitesse ? Lorsqu'il y a une condition de concurrence entre un plugin lié à une route et un autre plugin lié à un service, lequel doit prendre la priorité ? Ce sont toutes des choses que nous devons considérer en place.
Après avoir trié ces trois problèmes du plugin, nous pouvons obtenir un diagramme de flux interne du plugin :
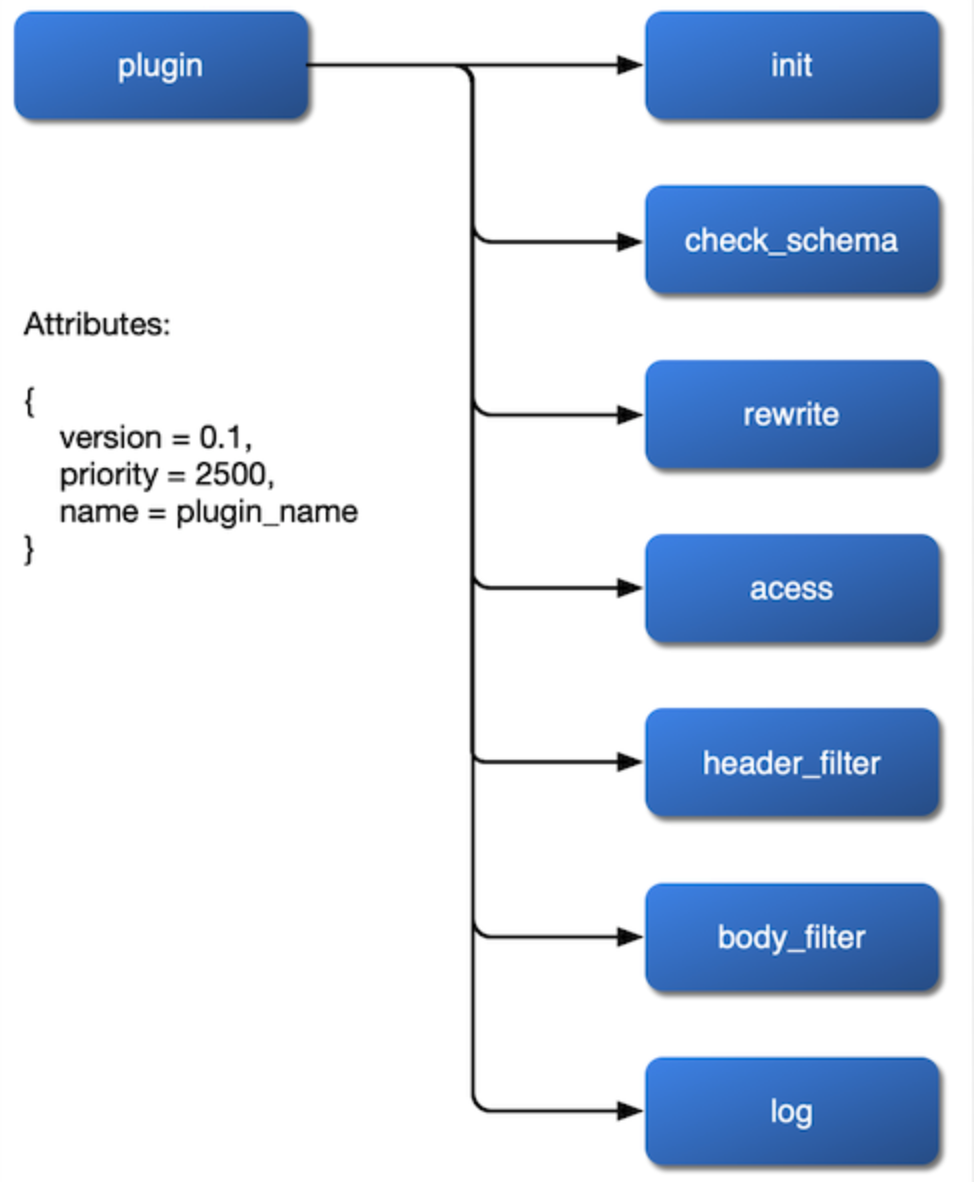{kind=link}
Infrastructure
Naturellement, lorsque ces composants critiques de la passerelle API de microservices sont déterminés, le flux de traitement des demandes des utilisateurs sera réglé. Ici, je dessine un diagramme pour montrer ce processus :
Diagramme du flux de traitement des demandes des utilisateurs
{kind=link}
De cette figure, nous pouvons voir que lorsqu'une demande d'utilisateur entre dans la passerelle API,
- Tout d'abord, les règles de routage seront comparées en fonction des méthodes de demande, de l'URI, de l'hôte et des conditions d'en-tête de demande. Si vous touchez une règle de routage, vous obtiendrez la liste des plugins correspondants à partir de etcd.
- Ensuite, il croise avec la liste des plugins ouverts localement pour obtenir la liste finale des plugins qui peuvent être exécutés.
- Et puis exécute les plugins un par un selon leur priorité.
- Enfin, la demande est envoyée à l'amont selon la vérification de santé de l'amont et l'algorithme de répartition de charge.
Nous serons prêts à écrire du code spécifique lorsque la conception de l'architecture sera terminée. C'est en fait comme construire une maison. Ce n'est qu'après avoir le plan et une fondation solide que vous pouvez faire le travail concret de construction de briques et de tuiles.
Résumé
En fait, à travers l'étude de ces deux articles, nous avons fait les deux choses les plus importantes de la localisation du produit et de la sélection de la technologie, qui sont plus critiques que l'implémentation spécifique du codage. Veuillez considérer et choisir plus soigneusement.
Alors, avez-vous déjà utilisé une passerelle API dans votre travail réel ? Comment votre entreprise choisit-elle la passerelle API ? N'hésitez pas à laisser un message et à partager votre expérience et vos gains avec moi. Vous êtes également invités à partager cet article avec plus de personnes afin que vous puissiez communiquer et progresser.
Précédent : Partie 1 : Comment construire une passerelle API de microservices en utilisant OpenResty Suivant : Partie 3 : Comment construire une passerelle API de microservices en utilisant OpenResty