Teil 2: Wie man ein Microservices-API-Gateway mit OpenResty erstellt
API7.ai
February 2, 2023
Nachdem wir die Kernkomponenten und Abstraktionen eines Microservices-API-Gateways verstanden haben, ist es an der Zeit, mit der technischen Auswahl und Implementierung zu beginnen. Heute werden wir die technische Auswahl der vier Kernkomponenten betrachten: Speicher, Routing, Schema und Plugins.
Speicher
Wie im vorherigen Artikel erwähnt, ist der Speicher eine sehr kritische Basiskomponente, die sich auf Kernfragen wie die Synchronisierung der Konfiguration, die Skalierung des Clusters und die Gewährleistung von Hochverfügbarkeit auswirkt. Daher steht er am Anfang des Auswahlprozesses.
Schauen wir uns an, wo bestehende API-Gateways ihre Daten speichern: Kong verwendet PostgreSQL oder Cassandra. Orange, ebenfalls basierend auf OpenResty, verwendet MySQL. Diese Optionen haben jedoch viele Nachteile.
Erstens muss der Speicher eine separate Hochverfügbarkeitslösung sein. PostgreSQL und MySQL haben ihre eigenen Hochverfügbarkeitslösungen, aber Sie benötigen auch DBA- und Maschinenressourcen, und ein schnelles Failover im Fehlerfall ist schwierig.
Zweitens können wir nur durch Abfragen der Datenbank Konfigurationsänderungen erhalten und keine Push-Benachrichtigungen durchführen. Dies erhöht den Ressourcenverbrauch der Datenbank und verringert die Echtzeitfähigkeit von Änderungen.
Drittens müssen Sie Ihre historischen Versionen pflegen und Rollbacks und Upgrades berücksichtigen. Wenn ein Benutzer eine Änderung veröffentlicht, kann es zu nachfolgenden Rollback-Operationen kommen, bei denen Sie auf Code-Ebene einen Diff zwischen den beiden Versionen für das Konfigurations-Rollback durchführen müssen. Außerdem kann ein System-Upgrade die Tabellenstruktur der Datenbank ändern, sodass der Code die Kompatibilität der alten und neuen Versionen sowie Daten-Upgrades berücksichtigen muss.
Viertens erhöht es die Komplexität des Codes. Neben der Implementierung der Gateway-Funktionalität müssen Sie die ersten drei Defizite des Codes patchen, was die Lesbarkeit des Codes erheblich verringert.
Fünftens erhöht es die Schwierigkeit der Bereitstellung, des Betriebs und der Wartung. Die Bereitstellung und Wartung einer relationalen Datenbank ist keine einfache Aufgabe, und es ist noch komplizierter, wenn es sich um einen Datenbankcluster handelt. Eine schnelle Skalierung ist nicht möglich.
Wie sollten wir in diesen Fällen wählen?
Gehen wir zurück zu den ursprünglichen Anforderungen des API-Gateways, wo einfache Konfigurationsinformationen wie URI, Plugin-Parameter, Upstream-Adressen usw. gespeichert werden. Es sind keine komplexen Join-Operationen erforderlich, und es gibt keine strengen Transaktionsgarantien. In diesem Fall ist die Verwendung einer relationalen Datenbank nicht "mit Kanonen auf Spatzen schießen", oder?
Tatsächlich ist die Minimierung der Verwendung von K8s und die Nähe zu etcd die richtige Wahl.
- Die Anzahl der Änderungen pro Sekunde in den Konfigurationsdaten des API-Gateways ist nicht groß, was etcd genügend Leistung bietet.
- Clustering und dynamische Skalierung sind inhärente Vorteile von etcd.
- etcd hat auch eine
watch-Schnittstelle, sodass Sie keine Abfragen durchführen müssen, um Änderungen zu erhalten.
Ein weiterer Beweis für die Zuverlässigkeit von etcd ist, dass es bereits die Standardwahl für die Speicherung von Konfigurationen im K8s-System ist und für viele komplexere Szenarien als API-Gateways validiert wurde.
Routing
Routing ist ebenfalls eine wichtige technische Auswahl, und alle Anfragen werden durch die Route zu der Liste der zu ladenden Plugins gefiltert, nacheinander ausgeführt und dann an den angegebenen Upstream weitergeleitet. Da es jedoch viele Routing-Regeln geben kann, müssen wir uns bei der technischen Auswahl des Routings auf die Zeitkomplexität des Algorithmus konzentrieren.
Schauen wir uns zunächst an, welche Routen unter OpenResty verfügbar sind. Wie üblich schauen wir im awesome-resty-Projekt nach, das spezielle Routing-Bibliotheken enthält:
• lua-resty-route — Eine URL-Routing-Bibliothek für OpenResty, die mehrere Route-Matcher, Middleware und HTTP- und WebSockets-Handler unterstützt, um einige ihrer Funktionen zu nennen • router.lua — Ein einfacher Router für Lua, der URLs abgleicht und Lua-Funktionen ausführt • lua-resty-r3 — libr3-Implementierung für OpenResty, libr3 ist eine leistungsstarke Pfadverteilungsbibliothek. Es kompiliert Ihre Routenpfade in einen Präfixbaum (Trie). Durch die Verwendung des konstruierten Präfixbaums zur Startzeit können Sie Ihre Routen effizient verteilen • lua-resty-libr3 — Leistungsstarke Pfadverteilungsbibliothek basierend auf libr3 für OpenResty
Wie Sie sehen, enthält dies die Implementierungen der vier Routing-Bibliotheken. Leider sind die ersten beiden Routings reine Lua-Implementierungen, die relativ einfach sind, sodass einige Funktionen fehlen, die den Anforderungen noch nicht gerecht werden.
Die letzten beiden Bibliotheken basieren tatsächlich auf der C-Bibliothek libr3 mit einer Schicht von FFI-Wrapping, während libr3 selbst einen Präfixbaum verwendet. Dieser Algorithmus hat nichts mit der Anzahl N der gespeicherten Regeln zu tun, sondern nur mit der Länge K der abzugleichenden Daten, sodass die Zeitkomplexität O(K) beträgt.
Allerdings hat libr3 seine Nachteile. Seine Abgleichregeln unterscheiden sich von denen des bekannten NGINX-Location, und es unterstützt keine Rückrufe. Dies lässt uns keine Möglichkeit, die Bedingungen für das Routing basierend auf Anfrage-Headern, Cookies und NGINX-Variablen festzulegen, was für API-Gateway-Szenarien offensichtlich nicht flexibel genug ist.
Obwohl unsere Versuche, eine verwendbare Routing-Bibliothek aus awesome-resty zu finden, erfolglos waren, weist die libr3-Implementierung uns in eine neue Richtung: die Implementierung von Präfixbäumen und FFI-Wrappern in C, was in Bezug auf Zeitkomplexität und Code-Leistung nahe an der optimalen Lösung liegen sollte.
Zufälligerweise haben die Autoren von Redis eine C-Implementierung des Radix-Baums open-source veröffentlicht, der ein komprimierter Präfixbaum ist. Wenn wir der Spur folgen, finden wir auch die FFI-Wrapper-Bibliothek für rax, die in OpenResty verfügbar ist und den folgenden Beispielcode hat:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
Wie Sie sehen können, unterstützt lua-resty-radixtree mehrere Dimensionen für die Routensuche basierend auf URI, Host, HTTP-Methode, HTTP-Header, NGINX-Variablen, IP-Adresse usw. Außerdem beträgt die Zeitkomplexität des Basisbaums O(K), was viel effizienter ist als der häufig verwendete Ansatz Traversierung + Hash-Cache.
Schema
Die Auswahl des Schemas ist viel einfacher. Das zuvor vorgestellte lua-rapidjson ist eine sehr gute Wahl. Sie müssen für diesen Teil nichts selbst schreiben; das JSON-Schema ist leistungsstark genug. Hier ist ein einfaches Beispiel:
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Plugin
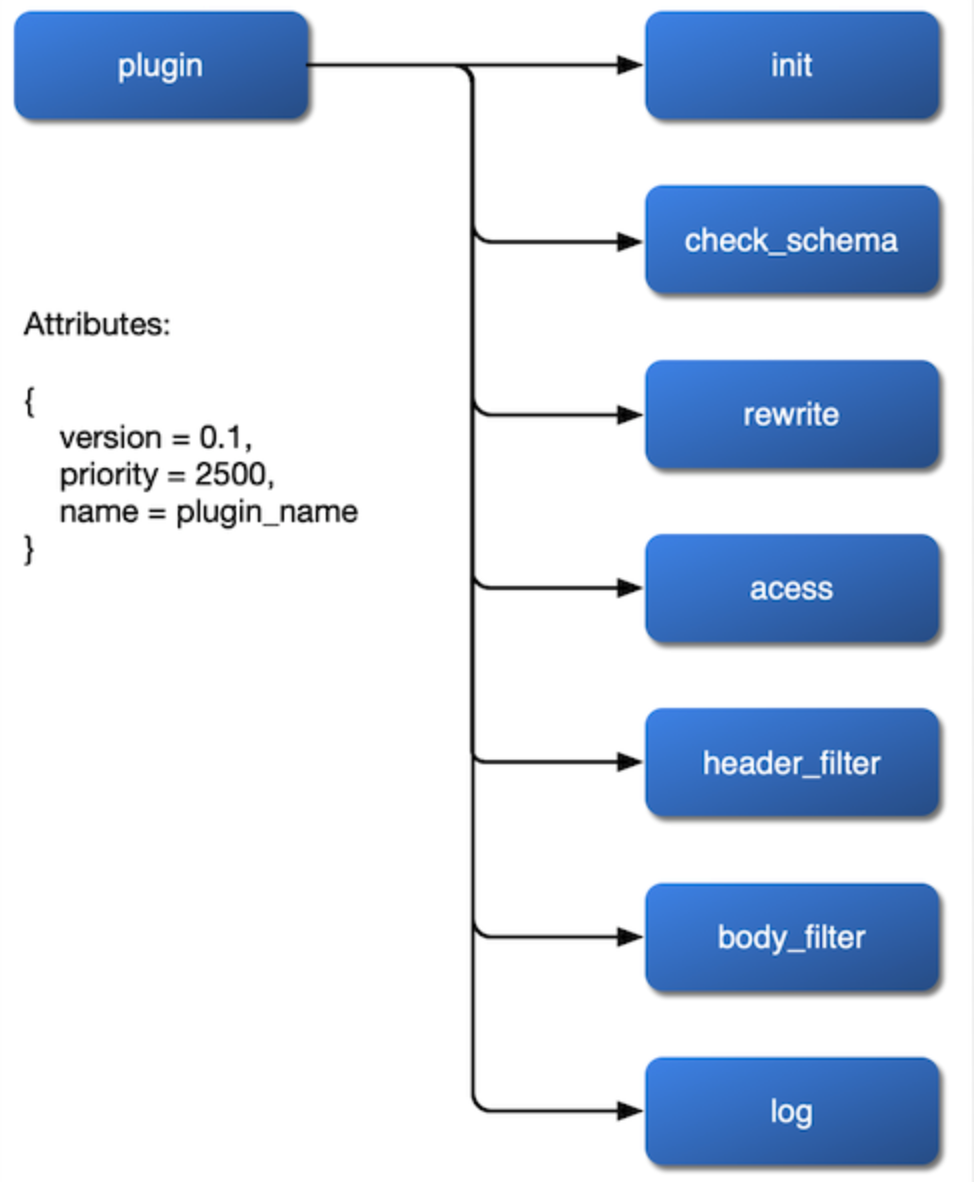
Mit der oben genannten Grundlage von Speicher, Routing und Schema ist viel klarer, wie die obere Schicht der Plugins implementiert werden sollte. Es gibt keine fertigen Open-Source-Bibliotheken für Plugins. Wir müssen sie selbst implementieren. Bei der Gestaltung von Plugins gibt es drei Hauptaspekte, die wir klar berücksichtigen müssen.
Das erste ist, wie man es einbindet. Wir möchten, dass das Plugin in die Phasen rewrite, access, header filter, body filter und log eingebunden wird und sogar seinen eigenen Lastausgleichsalgorithmus in der Balancer-Phase einrichtet. Daher sollten wir diese Phasen in der NGINX-Konfigurationsdatei freigeben und die Schnittstelle bei der Implementierung des Plugins offen lassen.
Das nächste ist, wie man Konfigurationsänderungen erhält. Da es keine relationalen Datenbankbeschränkungen gibt, können Änderungen an Plugin-Parametern über etcds watch implementiert werden, was den Gesamtcode des Frameworks viel transparenter und verständlicher macht.
Schließlich müssen wir die Priorität der Plugins berücksichtigen. Zum Beispiel, welches Plugin zuerst ausgeführt werden sollte: Authentifizierung oder Drosselung? Wenn es einen Wettlauf zwischen einem Plugin gibt, das an eine Route gebunden ist, und einem anderen Plugin, das an einen Dienst gebunden ist, welches sollte Vorrang haben? Dies sind alles Dinge, die wir berücksichtigen müssen.
Nachdem wir diese drei Probleme des Plugins geklärt haben, können wir ein Flussdiagramm des internen Ablaufs des Plugins erstellen:
{kind=link}
Infrastruktur
Natürlich, wenn diese kritischen Komponenten des Microservices-API-Gateways festgelegt sind, wird der Verarbeitungsfluss von Benutzeranfragen festgelegt. Hier zeichne ich ein Diagramm, um diesen Prozess zu zeigen:
Diagramm des Verarbeitungsflusses von Benutzeranfragen
{kind=link}
Aus dieser Abbildung können wir sehen, dass, wenn eine Benutzeranfrage in das API-Gateway eintritt,
- Zuerst werden die Routing-Regeln basierend auf den Anfragemethoden, URI, Host und Anfrage-Header-Bedingungen abgeglichen. Wenn eine Routing-Regel getroffen wird, erhalten Sie die entsprechende Plugin-Liste von etcd.
- Dann wird sie mit der lokal geöffneten Plugin-Liste geschnitten, um die endgültige Liste der ausführbaren Plugins zu erhalten.
- Und dann werden die Plugins nacheinander entsprechend ihrer Priorität ausgeführt.
- Schließlich wird die Anfrage basierend auf der Upstream-Gesundheitsprüfung und dem Lastausgleichsalgorithmus an den Upstream gesendet.
Wir werden bereit sein, spezifischen Code zu schreiben, wenn das Architekturdesign abgeschlossen ist. Dies ist tatsächlich wie der Bau eines Hauses. Nur wenn Sie den Bauplan und ein solides Fundament haben, können Sie die konkrete Arbeit des Ziegel- und Dachziegelbaus erledigen.
Zusammenfassung
Tatsächlich haben wir durch das Studium dieser beiden Artikel die beiden wichtigsten Dinge der Produktpositionierung und Technologieauswahl erledigt, die kritischer sind als die spezifische Code-Implementierung. Bitte überlegen und wählen Sie sorgfältiger.
Haben Sie also jemals ein API-Gateway in Ihrer tatsächlichen Arbeit verwendet? Wie wählt Ihr Unternehmen das API-Gateway aus? Hinterlassen Sie eine Nachricht und teilen Sie Ihre Erfahrungen und Erkenntnisse mit mir. Sie sind auch eingeladen, diesen Artikel mit mehr Menschen zu teilen, damit Sie kommunizieren und Fortschritte machen können.
Vorheriger Artikel: Teil 1: Wie man ein Microservices-API-Gateway mit OpenResty baut Nächster Artikel: Teil 3: Wie man ein Microservices-API-Gateway mit OpenResty baut