Building an AI Agent Traffic Management Platform: APISIX AI Gateway in Practice
November 18, 2025
Introduction: The Turning Point from Dispersed Traffic to Intelligent Governance
Since early 2025, within a leading global appliance giant, multiple business lines have introduced numerous large language models (LLMs). The R&D department needed coding assistants to improve efficiency, the marketing team focused on content generation, and the smart product team aimed to integrate conversational capabilities into home appliances. The variety of models rapidly expanded to include both self-built solutions like DeepSeek and Qwen, as well as proprietary models from multiple cloud service providers.
However, this rapid expansion soon exposed new bottlenecks: fragmented inference traffic, chaotic scheduling, rising operational costs, and uncontrollable stability issues.
The infrastructure team realized they needed a central system capable of unified control and dynamic scheduling at the traffic layer—a gateway born for AI.
Thus, the enterprise began collaborating with the API7 team to jointly build an enterprise-grade AI Agent traffic management and scheduling platform. This was not just an upgrade in gateway technology, but a comprehensive architectural transformation for the AI era.
Challenges: The Complexity of Multi-Model, Multi-Tenant, Hybrid Cloud
In this appliance giant's AI practice, challenges are primarily focused on four levels:
1. Stability Assurance
- With rapid model iterations and service diversification, how to ensure stable proxying and quick recovery for each request?
- How to achieve zero-interruption switching between different vendors' LLM services?
2. Multi-tenant Isolation
- Each business department operated independent AI Agents. When tasks from one tenant spiraled out of control, resource and fault isolation became essential to prevent chain reactions.
3. Intelligent Scheduling
- The hybrid cloud architecture coexisted with self-built models and cloud models. Facing dynamic loads, the system lacked real-time health awareness and automatic routing optimization.
4. Content and Compliance Security
- Faced with the risk of malicious user input leading to the generation of harmful content, it is necessary to establish a real-time content filtering system to meet global compliance requirements and thus protect brand reputation.
These problems collectively pointed to a core requirement: AI traffic must be uniformly governed, visually monitored, and intelligently scheduled.
System Design: Core Architecture of the AI Gateway
The enterprise chose to build AI gateway capabilities on top of its existing API gateway, transforming it into a unified intelligent traffic hub.
From an overall perspective, the system comprises three core layers:
- Access Layer: Provides unified entry points, handling protocol conversion, authentication, and rate limiting.
- Governance Layer: Implements dynamic routing, circuit breaking, fault detection, and content filtering through a plugin mechanism.
- Scheduling Layer: Combines health checks with real-time load information to enable automatic switching between self-built and cloud models.

On the AI gateway, some AI models undergo rapid version iterations with stability risks. For example, improper request formats might trigger model loops, persistent abnormal outputs, or generate unreasonable content. Therefore, the internal technical team leveraged APISIX AI Gateway's plugin extension mechanism. Through custom plugins for request rewriting and defense, along with flexible configuration, they implemented intervention and filtering of request and response content to ensure service reliability and output quality.
Key Selection Criteria for AI Gateways
In the process of building AI capability platforms, gateway selection significantly impacts the overall architecture. The enterprise evaluated solutions based on several core dimensions:
-
Production-Grade Stability: Stability is paramount. Ensuring service stability for users, enabling business operations to continue uninterrupted even during model fluctuations, is the most critical requirement.
-
Continuously Evolving Technical Capabilities: With AI technology iterating rapidly, the AI gateway must maintain fast update cycles to promptly adapt to new model protocols and interaction patterns. The chosen AI gateway needs to keep pace with technological trends, avoiding becoming a bottleneck for business innovation.
-
Standardized, Reusable Architecture: Mature, reusable architecture is another key point. Providing standard API management and extension interfaces that comply with mainstream technical standards and best practices. APISIX AI Gateway's extensibility stood out as a highlight, directly determining integration costs with existing technology stacks and the smoothness of future integration into broader AI ecosystems.
Fine-Grained AI Traffic Governance and Multi-tenant Isolation
Scenario 1: Automatic Fallback for Hybrid Models
In actual usage, this leading appliance enterprise adopted a hybrid deployment model for critical models (Model A): part of the service was self-built in private data centers, served as the main carrier for core traffic; simultaneously, using this model on public cloud with pay-as-you-go pricing served as Plan B.
All requests were initially directed to self-built services by default. When self-built services encountered performance bottlenecks or became unavailable due to sudden traffic spikes or peaks, the gateway—based on preset token rate limiting policies and real-time health checks—automatically and seamlessly switched requests to cloud services, achieving smooth fallback. Once self-built services recovered, traffic automatically reverted.
curl "http://127.0.0.1:9180/apisix/admin/routes" -X PUT \ -H "X-API-KEY: ${ADMIN_API_KEY}" \ -d '{ "id": "ai-proxy-multi-route", "uri": "/anything", "methods": ["POST"], "plugins": { "ai-proxy-multi": { "balancer": { "algorithm": "roundrobin", "hash_on": "vars" }, "fallback_strategy": "instance_health_and_rate_limiting", "instances": [ { "auth": { "header": { "Authorization": "Bearer {ALIYUN_API_KEY}" } }, "name": "qwen2.5-32b-instruct-ali-bailian", "options": { "model": "qwen2.5-32b-instruct" }, "override": { "endpoint": "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions" }, "priority": 1, "provider": "openai-compatible", "weight": 100 }, { "auth": { "header": { "Authorization": "Bearer {CUSTOM_API_KEY}" } }, "checks": { "active": { "concurrency": 10, "healthy": { "http_statuses": [ 200, 302 ], "interval": 30, "successes": 1 }, "host": "{CUSTOM_HOST_1}:{CUSTOM_PORT_1}", "http_method": "POST", "http_path": "/v1/chat/completions", "http_req_body": "{\"model\":\"Qwen/Qwen2.5-32B-Instruct\",\"messages\":[{\"role\":\"user\",\"content\":\"0\"}],\"stream\":false,\"max_tokens\":1}", "https_verify_certificate": false, "req_headers": [ "Content-Type: application/json" ], "request_body": "", "timeout": 2, "type": "http", "unhealthy": { "http_failures": 1, "http_statuses": [ 404, 429, 500, 501, 502, 503, 504, 505 ], "interval": 30, "tcp_failures": 2, "timeouts": 2 } } }, "name": "qwen2.5-32b-instruct-b", "options": { "model": "Qwen/Qwen2.5-32B-Instruct" }, "override": { "endpoint": "http://{CUSTOM_HOST_1}:{CUSTOM_PORT_1}/v1/chat/completions" }, "priority": 5, "provider": "openai-compatible", "weight": 100 }, { "auth": { "header": { "Authorization": "Bearer {NLB_API_KEY}" } }, "checks": { "active": { "concurrency": 10, "healthy": { "http_statuses": [ 200, 302 ], "interval": 30, "successes": 1 }, "host": "{CUSTOM_NLB_HOST}:{CUSTOM_NLB_PORT}", "http_method": "POST", "http_path": "/v1/chat/completions", "http_req_body": "{\"model\":\"Qwen/Qwen2.5-32B-Instruct\",\"messages\":[{\"role\":\"user\",\"content\":\"0\"}],\"stream\":false,\"max_tokens\":1}", "https_verify_certificate": false, "req_headers": [ "Content-Type: application/json" ], "request_body": "", "timeout": 3, "type": "http", "unhealthy": { "http_failures": 2, "http_statuses": [ 404, 429, 500, 501, 502, 503, 504, 505 ], "interval": 30, "tcp_failures": 2, "timeouts": 3 } } }, "name": "qwen2.5-32b-instruct-c", "options": { "model": "Qwen/Qwen2.5-32B-Instruct" }, "override": { "endpoint": "http://{CUSTOM_NLB_HOST}:{CUSTOM_NLB_PORT}/v1/chat/completions" }, "priority": 10, "provider": "openai-compatible", "weight": 100 } ], "keepalive": true, "keepalive_pool": 30, "keepalive_timeout": 4000, "ssl_verify": false, "timeout": 600000 }

This mechanism operated fully automated, ensuring business continuity. Operations teams only became aware of state transitions through alerts, requiring no manual intervention. This capability not only significantly enhanced business continuity but also greatly reduced operational complexity, becoming key infrastructure for ensuring AI service high availability.
Scenario 2: Token-Based Rate Limiting
In this enterprise's AI service multi-tenant architecture, reasonable resource allocation and isolation between different users were the most core requirements. Since token costs varied significantly across different AI models, traditional request-based rate limiting couldn't accurately measure real resource consumption. Therefore, it was essential to introduce fine-grained quota management and traffic control mechanisms based on token volume, thereby truly reflecting resource consumption and ensuring reasonable scheduling and cost control between users.
In this mechanism, different consumers had independent rate-limiting quotas, while different LLMs had separate token limits. Both took effect simultaneously, with consumer quotas having higher priority than LLM quotas. Once quotas were exhausted, consumers were prohibited from continuing to call LLM services.

For example, LLM A has a global token limit of 50,000 tokens per hour, shared by three consumers with individual quotas: Consumer A (10,000 tokens), Consumer B (20,000 tokens), and Consumer C (5,000 tokens). Before the new requests shown in the diagram, Consumer A had already used 8,500 of its quota, Consumer B had used 15,200, and Consumer C had used 4,600, contributing to a global total of 49,300 tokens used.
When consumers sent requests, the gateway would sequentially check both quotas: first verifying whether individual consumer quotas were sufficient, then confirming whether global LLM quotas were adequate. Only when both conditions were met would requests be forwarded to LLMs; insufficient quotas in either category would immediately return 429 errors and reject requests.
sequenceDiagram
participant C1 as Consumer A<br/>Quota: 10K tokens/hour
participant C2 as Consumer B<br/>Quota: 20K tokens/hour
participant C3 as Consumer C<br/>Quota: 5K tokens/hour
participant G as APISIX AI Gateway
participant R as Redis
participant LLM as LLM A<br/>Global: 50K tokens/hour
Note over G, R: Current State: LLM Used = 49,300/50,000 tokens
par Consumer A needs 150 tokens
C1->>G: Request (150 tokens)
G->>R: Check C1 quota: 8,500 + 150 = 8,650 ≤ 10,000 ✅
G->>R: Check LLM quota: 49,300 + 150 = 49,450 ≤ 50,000 ✅
G->>LLM: Forward (both quotas OK)
LLM-->>C1: Success
and Consumer B needs 320 tokens
C2->>G: Request (320 tokens)
G->>R: Check C2 quota: 15,200 + 320 = 15,520 ≤ 20,000 ✅
G->>R: Check LLM quota: 49,300 + 320 = 49,620 ≤ 50,000 ✅
G->>LLM: Forward (both quotas OK)
LLM-->>C2: Success
and Consumer C needs 800 tokens
C3->>G: Request (800 tokens)
G->>R: Check C3 quota: 4,600 + 800 = 5,400 > 5,000 ❌
G-->>C3: 429 Error (exceeds consumer quota)
end
In practical configuration, first enable the ai-proxy-multi and ai-rate-limiting plugins to set up rate limiting for the LLM.
curl "http://127.0.0.1:9180/apisix/admin/routes" -X PUT \ -H "X-API-KEY: ${ADMIN_API_KEY}" \ -d '{ "id": "ai-proxy-multi-route", "uri": "/anything", "methods": ["POST"], "plugins": { "key-auth": {}, "ai-proxy-multi": { "instances": [ { "name": "qwen2.5-32b-instruct-ali-bailian", "options": { "model": "qwen2.5-32b-instruct" }, "auth": { "header": { "Authorization": "Bearer {NLB_API_KEY}" } }, "override": { "endpoint": "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions" }, "priority": 1, "provider": "openai-compatible", "weight": 100 }, { "name": "qwen2.5-32b-instruct-b", "options": { "model": "Qwen/Qwen2.5-32B-Instruct" }, "auth": { "header": { "Authorization": "Bearer {NLB_API_KEY}" } }, "override": { "endpoint": "http://{CUSTOM_HOST_1}:{CUSTOM_PORT_1}/v1/chat/completions" }, "priority": 5, "provider": "openai-compatible", "weight": 100 } ] }, "ai-rate-limiting": { "instances": [ { "name": "qwen2.5-32b-instruct-ali-bailian", "limit": 50000, "time_window": 3600 }, { "name": "qwen2.5-32b-instruct-b", "limit": 50000, "time_window": 3600 } ], "rejected_code": 429, "limit_strategy": "total_tokens" } }
Then, create three consumers and configure corresponding rate limiting for each. The ai-consumer-rate-limiting plugin is specifically used to enforce rate limits on consumers. Taking Consumer A as an example, the configuration is as follows:
curl "http://127.0.0.1:9180/apisix/admin/consumers" -X PUT \ -H "X-API-KEY: ${ADMIN_API_KEY}" \ -d '{ "username": "consumer_a", "plugins": { "key-auth": { "key": "consumer_a_key" }, "ai-consumer-rate-limiting": { "instances": [ { "name": "qwen2.5-32b-instruct-ali-bailian", "limit_strategy": "total_tokens", "limit": 10000, "time_window": 3600 }, { "name": "qwen2.5-32b-instruct-b", "limit_strategy": "total_tokens", "limit": 10000, "time_window": 3600 } ], "rejected_code": 429, "rejected_msg": "Insufficient token, try in one hour." } } }'
This solution effectively prevents individual consumers from excessive consumption affecting other users, protects backend LLM instances from being overwhelmed by sudden traffic spikes, manages quotas based on actual token consumption, and provides differentiated services for different user levels.
Securing AI Conversations for Smart Homes
Scenario 3: Content Security Filtering
After launching its public-facing services, the company observed through monitoring systems that a small subset of users were intentionally inputting harmful content or attempting to manipulate the AI into generating responses related to violence, prohibited substances, self-harm, and other dangerous materials. For example:
- Users queried the ingredient assistant of a "smart refrigerator" for hazardous recipes or dangerous operations, such as asking: "How can I create explosives using household chemicals?"
- Individuals input prompts containing violent or inappropriate behavior into a story generation feature integrated with a children's eye-protection lamp.
If such content be processed or generated by the AI, it would not only constitute a clear violation of legal and regulatory requirements but also expose the enterprise—whose brand identity centers on "family-friendliness"—to severe reputational damage and significant legal liability.
To address this critical challenge, the home appliance enterprise implemented the ai-aliyun-content-moderation plugin from APISIX AI Gateway. This solution enabled them to establish a comprehensive, zero-trust architecture for bidirectional content filtering atop their existing intelligent traffic management layer:
- Request Layer Interception: The system performs real-time interception of user prompts before they are transmitted to backend large language models for inference, eliminating risks at the source and preventing wasteful consumption of computational resources.
- Response Layer Validation: All content generated by the AI models undergoes a secondary review process, serving as the final security checkpoint before reaching end users and ensuring that model "hallucinations" or anomalous outputs do not compromise user experience.
The following diagram illustrates the architecture of this dual-layer security approach:
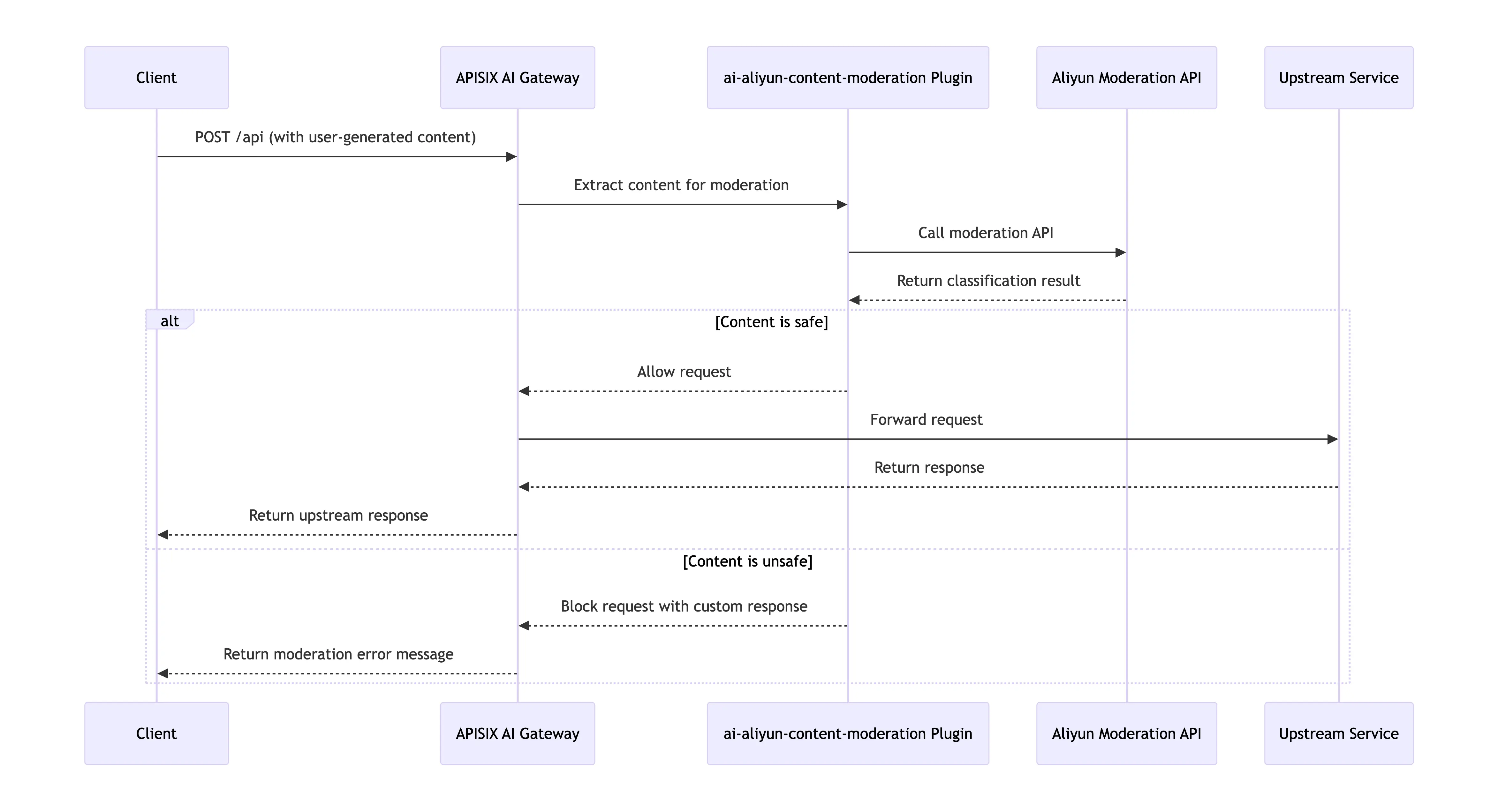
Below is a practical configuration example demonstrating how to set up the content security plugin for a smart home appliance AI service route.
curl "http://127.0.0.1:9180/apisix/admin/routes" -X PUT \ -H "X-API-KEY: ${ADMIN_API_KEY}" \ -d '{ "id": "ai-aliyun-content-moderation-route", "uri": "/anything", "methods": ["POST"], "plugins": { "ai-proxy-multi": { "instances": [ { "name": "openai-instance", "provider": "openai", "weight": 8, "auth": { "header": { "Authorization": "Bearer '"$OPENAI_API_KEY"'" } }, "options": { "model": "gpt-4" } }, { "name": "deepseek-instance", "provider": "deepseek", "weight": 2, "auth": { "header": { "Authorization": "Bearer '"$DEEPSEEK_API_KEY"'" } }, "options": { "model": "deepseek-chat" } } ] }, "ai-aliyun-content-moderation": { "endpoint": "'"$ALIYUN_ENDPOINT"'", "region_id": "'"$ALIYUN_REGION_ID"'", "access_key_id": "'"$ALIYUN_ACCESS_KEY_ID"'", "access_key_secret": "'"$ALIYUN_ACCESS_KEY_SECRET"'", "deny_code": 400, "deny_message": "Content violates safety guidelines for smart home devices." } } }'
Value Delivered by APISIX AI Gateway
By building a unified AI gateway and consolidating AI traffic entry points, the technical team significantly improved the overall usage efficiency and management capability of model services. Main achievements include the following aspects:
1. Simplified Large Model Access, Lowering Usage Barriers
The AI gateway provides unified access addresses and keys for all model services. Users don't need to concern themselves with backend model deployment and operational details—they can flexibly call various model resources through fixed entry points, greatly reducing the barrier to using AI capabilities.
2. Achieved Centralized Resource Management with Service Stability
Without a unified AI gateway, various business units would need to build and maintain model services independently. Particularly when facing high resource consumption scenarios like large models, this would lead to duplicated GPU investments and waste. Through unified management and scheduling, efficient resource utilization was achieved, with service stability centrally guaranteed at the gateway level.
3. Unified Control with Traffic Security Assurance
As the unified consolidation point for all AI traffic, the AI gateway became the critical node for implementing common capabilities. At this node, identity authentication, access auditing, content security review, abnormal request protection, and output content filtering could be centrally implemented, systematically enhancing overall platform controllability and security.
4. Proactive Content Risk Prevention
By integrating security plugins such as ai-aliyun-content-moderation, the AI gateway transforms content security from fragmented, post-event application-layer reviews into a unified, real-time proactive defense system at the gateway level. This solidifies the security foundation for consumer-facing smart home AI services.
AI Gateway Evolution Direction and Outlook
As AI integrates into all aspects of R&D, manufacturing, and sales, this industry benchmark enterprise's goal is shifting from "connecting models" to "building a unified AI platform." In this process, the AI gateway is no longer just a traffic distribution node but is gradually evolving into the scheduling core of the entire AI capability system. In the future, it will carry new capabilities, including MCP (Model Context Protocol) and Agent2Agent (A2A) protocol, evolving into the enterprise's AI operating system kernel.
For this appliance enterprise, the current phase focuses on building foundations: making every request observable, schedulable, and governable.
While deeply applying APISIX AI Gateway in business scenarios, both parties are also jointly exploring evolution directions for next-generation AI infrastructure. As AI-native workloads like large model inference gradually become core business traffic, the team observed in practice that AI traffic exhibits significant differences from traditional web traffic in scheduling sensitivity, response patterns, and service governance dimensions. This presents new propositions for the gateway's continuous evolution:
-
More Intelligent Traffic Scheduling: Current load balancing strategies excel at handling high-concurrency, fast-response traditional traffic. For AI services, we hope to introduce metrics like GPU load, inference queue depth, and single-request latency to achieve intelligent distribution based on real-time service capabilities, making resource utilization more efficient and responses more stable.
-
Backend Service State Awareness: When model services experience slowed responses or queue buildup, the gateway should detect and switch faster. We're exploring how to implement dynamic routing based on real-time service states, such as inference performance and queue length, to ensure smooth user experiences.
-
Completing Observability Data: The plugin architecture provides flexibility for traffic governance. Next, the technical team hopes to further enhance the gateway's fine-grained metric collection capabilities, such as upstream service status codes and precise response latency, making it more naturally integrated into existing monitoring and logging systems, providing solid support for fault localization and system optimization.
In an era where AI traffic becomes an enterprise-critical workload, API7 and this globally leading multinational appliance giant have jointly explored an evolution path of "gateway intelligence." It represents both a technological upgrade and an organizational capability transformation—making AI truly become an enterprise's underlying operational capability, rather than a passive tool.