파트 2: OpenResty를 사용하여 마이크로서비스 API 게이트웨이 구축하기
API7.ai
February 2, 2023
마이크로서비스 API 게이트웨이의 핵심 구성 요소와 추상화를 이해한 후, 이제 기술 선택을 시작하고 구현할 차례입니다. 오늘은 저장소, 라우팅, 스키마, 플러그인이라는 네 가지 핵심 구성 요소의 기술 선택을 각각 살펴보겠습니다.
저장소
이전 글에서 언급했듯이, 저장소는 가장 하단에 위치한 매우 중요한 기본 구성 요소로, 설정을 어떻게 동기화할지, 클러스터를 어떻게 확장할지, 고가용성을 어떻게 보장할지와 같은 핵심 문제에 영향을 미칩니다. 따라서 우리는 이를 선택 과정의 가장 처음에 배치했습니다.
기존 API 게이트웨이들이 데이터를 어디에 저장하는지 살펴봅시다: Kong은 PostgreSQL 또는 Cassandra를 사용하고, OpenResty 기반의 Orange는 MySQL을 사용합니다. 그러나 이러한 선택에는 여러 단점이 있습니다.
첫째, 저장소는 별도의 고가용성 솔루션이어야 합니다. PostgreSQL과 MySQL 데이터베이스는 자체적인 고가용성 솔루션을 가지고 있지만, DBA와 머신 리소스도 필요하며, 장애 발생 시 빠른 전환이 어렵습니다.
둘째, 데이터베이스를 폴링하여 설정 변경을 가져올 수만 있고, 푸시를 할 수 없습니다. 이는 데이터베이스 리소스 소비를 증가시키고 변경의 실시간성을 떨어뜨립니다.
셋째, 사용자가 변경을 배포한 후 롤백 작업이 필요할 수 있으며, 이때 코드 수준에서 두 버전 간의 차이를 계산하여 설정 롤백을 수행해야 합니다. 또한 시스템 업그레이드 시 데이터베이스 테이블 구조가 변경될 수 있으므로, 코드는 이전 및 새 버전의 호환성과 데이터 업그레이드를 고려해야 합니다.
넷째, 코드의 복잡성이 증가합니다. 게이트웨이의 기능을 구현하는 것 외에도, 앞서 언급한 세 가지 결함을 코드로 패치해야 하므로 코드의 가독성이 크게 떨어집니다.
다섯째, 배포와 운영, 유지보수의 어려움이 증가합니다. 관계형 데이터베이스를 배포하고 유지보수하는 것은 간단한 작업이 아니며, 데이터베이스 클러스터라면 더욱 복잡합니다. 빠른 확장이 불가능합니다.
이러한 경우에 우리는 어떻게 선택해야 할까요?
API 게이트웨이의 원래 요구 사항으로 돌아가보면, URI, 플러그인 매개변수, 업스트림 주소 등과 같은 간단한 설정 정보를 저장하는 것이며, 복잡한 조인 연산이 필요하지 않고 엄격한 트랜잭션 보장도 필요하지 않습니다. 이 경우 관계형 데이터베이스를 사용하는 것은 "닭 잡는데 소 잡는 칼을 쓰는" 것과 같지 않을까요?
사실, K8s를 최소화하고 etcd에 더 가깝게 유지하는 것이 올바른 선택입니다.
- API 게이트웨이의 설정 데이터는 초당 변경 횟수가 많지 않아 etcd의 성능이 충분합니다.
- 클러스터링과 동적 확장은 etcd의 고유한 장점입니다.
- etcd는
watch인터페이스를 제공하므로 변경 사항을 폴링할 필요가 없습니다.
또한 etcd의 신뢰성을 증명하는 것은, 이미 K8s 시스템에서 설정을 저장하는 기본 선택으로 사용되고 있으며, API 게이트웨이보다 훨씬 더 복잡한 시나리오에서 검증되었다는 점입니다.
라우팅
라우팅도 중요한 기술 선택 사항입니다. 모든 요청은 라우팅을 통해 필터링되어 로드해야 할 플러그인 목록을 얻고, 이를 하나씩 실행한 후 지정된 업스트림으로 전달됩니다. 그러나 라우팅 규칙이 많을 수 있으므로, 여기서는 라우팅의 기술 선택에 있어 알고리즘의 시간 복잡도에 초점을 맞춰야 합니다.
먼저 OpenResty에서 사용 가능한 라우팅 라이브러리를 살펴보겠습니다. awesome-resty 프로젝트에서 각각을 찾아보면 다음과 같은 특별한 라우팅 라이브러리가 있습니다:
• lua-resty-route — URL 라우팅 라이브러리로, 여러 라우팅 매처, 미들웨어, HTTP 및 WebSocket 핸들러 등을 지원 • router.lua — Lua를 위한 기본적인 라우터로, URL을 매치하고 Lua 함수를 실행 • lua-resty-r3 — libr3의 OpenResty 구현으로, libr3는 고성능 경로 디스패치 라이브러리입니다. 라우팅 경로를 접두사 트리(trie)로 컴파일하며, 시작 시점에 구성된 접두사 트리를 사용하여 효율적으로 라우팅을 디스패치할 수 있습니다. • lua-resty-libr3 — libr3 기반의 고성능 경로 디스패치 라이브러리
보시다시피, 이 네 가지 라우팅 라이브러리의 구현이 포함되어 있습니다. 불행히도, 처음 두 라우팅은 순수 Lua 구현으로 상대적으로 단순하여 아직 세대 요구 사항을 충족하지 못하는 기능이 많이 부족합니다.
후자의 두 라이브러리는 실제로 C 라이브러리 libr3를 기반으로 FFI를 사용하여 래핑한 것이며, libr3 자체는 접두사 트리를 사용합니다. 이 알고리즘은 저장된 규칙의 수 N과는 무관하며, 매칭 데이터의 길이 K에만 관련이 있으므로 시간 복잡도는 O(K)입니다.
그러나 libr3에는 단점이 있습니다. 익숙한 NGINX location과는 다른 매칭 규칙을 가지고 있으며, 콜백을 지원하지 않습니다. 이로 인해 요청 헤더, 쿠키, NGINX 변수 등을 기반으로 라우팅 조건을 설정할 수 없어 API 게이트웨이 시나리오에서는 충분히 유연하지 않습니다.
그러나 awesome-resty에서 사용 가능한 라우팅 라이브러리를 찾는 시도는 실패했지만, libr3 구현은 새로운 방향을 제시합니다: C로 접두사 트리와 FFI 래퍼를 구현하는 것이 시간 복잡도와 코드 성능 면에서 최적의 솔루션에 가까울 것입니다.
Redis의 저자가 radix tree의 C 구현을 오픈소스로 공개했는데, 이는 압축된 접두사 트리입니다. 이를 따라가면 OpenResty에서 사용 가능한 rax의 FFI 래퍼 라이브러리를 찾을 수 있으며, 다음과 같은 샘플 코드가 있습니다:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
보시다시피, lua-resty-radixtree는 URI, 호스트, HTTP 메서드, HTTP 헤더, NGINX 변수, IP 주소 등 여러 차원에서 라우팅 조회를 지원합니다. 또한 기본 트리의 시간 복잡도는 O(K)로, 일반적으로 사용되는 순회 + 해시 캐시 방식보다 훨씬 효율적입니다.
스키마
스키마 선택은 훨씬 쉽습니다. 이전에 소개한 lua-rapidjson은 매우 좋은 선택입니다. 이 부분을 위해 직접 작성할 필요는 없으며, JSON 스키마는 충분히 강력합니다. 다음은 간단한 예제입니다.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
플러그인
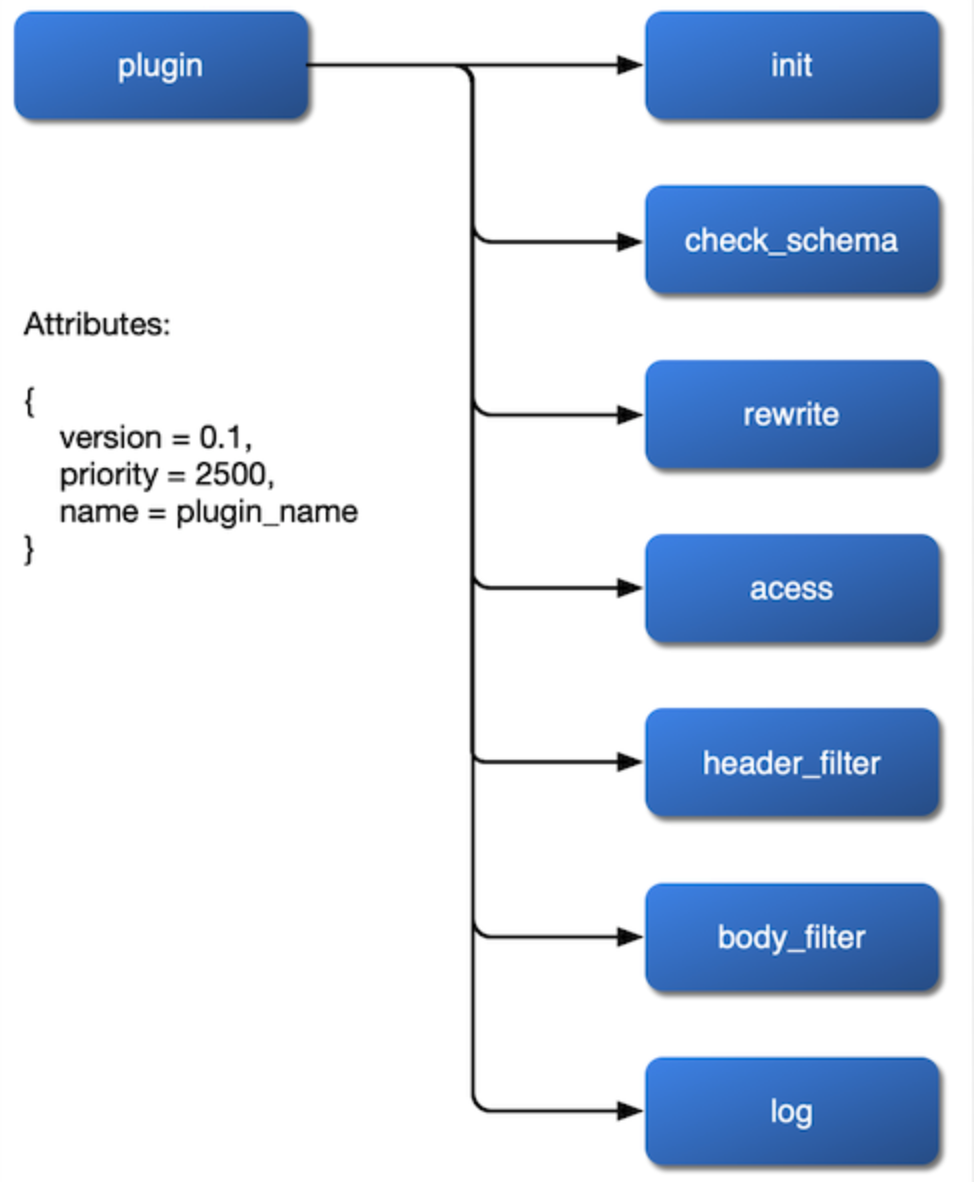
위에서 설명한 저장소, 라우팅, 스키마의 기반을 바탕으로, 상위 계층의 플러그인을 어떻게 구현해야 하는지가 훨씬 명확해졌습니다. 플러그인에는 사용할 수 있는 오픈소스 라이브러리가 없으므로 직접 구현해야 합니다. 플러그인을 설계할 때는 세 가지 주요 측면을 명확히 고려해야 합니다.
첫 번째는 어떻게 마운트할지입니다. 우리는 플러그인이 rewrite, access, header filter, body filter, log 단계에 마운트되고, 심지어 balancer 단계에서 자체 로드 밸런싱 알고리즘을 설정할 수 있기를 원합니다. 따라서 NGINX 설정 파일에서 이러한 단계를 노출하고, 플러그인 구현 시 인터페이스를 열어두어야 합니다.
다음은 설정 변경을 어떻게 가져올지입니다. 관계형 데이터베이스의 제약이 없으므로, 플러그인 매개변수의 변경은 etcd의 watch를 통해 구현할 수 있으며, 이는 전체 프레임워크 코드 로직을 훨씬 더 명확하고 이해하기 쉽게 만듭니다.
마지막으로, 플러그인의 우선순위를 고려해야 합니다. 예를 들어, 인증과 속도 제한 중 어떤 플러그인을 먼저 실행해야 할까요? 라우팅에 바인딩된 플러그인과 서비스에 바인딩된 플러그인 간에 경쟁 조건이 발생할 경우, 어떤 것이 우선해야 할까요? 이러한 사항들을 모두 고려해야 합니다.
이 세 가지 문제를 정리한 후, 플러그인의 내부 흐름도를 얻을 수 있습니다:
{kind=link}
인프라
이러한 마이크로서비스 API 게이트웨이의 핵심 구성 요소가 결정되면, 사용자 요청의 처리 흐름도 결정됩니다. 이를 보여주기 위해 다이어그램을 그렸습니다:
{kind=link}
이 그림에서 볼 수 있듯이, 사용자 요청이 API 게이트웨이에 들어오면,
- 먼저 요청 메서드, URI, 호스트, 요청 헤더 조건에 따라 라우팅 규칙이 매칭됩니다. 라우팅 규칙에 맞으면 etcd에서 해당 플러그인 목록을 가져옵니다.
- 그런 다음 로컬에서 열린 플러그인 목록과 교차하여 실행 가능한 최종 플러그인 목록을 얻습니다.
- 그리고 플러그인의 우선순위에 따라 하나씩 실행합니다.
- 마지막으로, 업스트림의 건강 상태 검사와 로드 밸런싱 알고리즘에 따라 요청을 업스트림으로 전송합니다.
아키텍처 설계가 완료되면 구체적인 코드를 작성할 준비가 됩니다. 이는 집을 짓는 것과 같습니다. 청사진과 견고한 기반이 있어야 벽돌과 타일을 쌓는 구체적인 작업을 할 수 있습니다.
요약
사실, 이 두 글을 통해 우리는 제품 포지셔닝과 기술 선택이라는 가장 중요한 두 가지 작업을 수행했습니다. 이는 구체적인 코딩 구현보다 더 중요합니다. 더 신중하게 고려하고 선택하시기 바랍니다.
그렇다면, 실제 업무에서 API 게이트웨이를 사용해 본 적이 있나요? 귀하의 회사는 어떻게 API 게이트웨이를 선택하나요? 의견을 남기고 경험과 얻은 점을 공유해 주세요. 이 글을 더 많은 사람들과 공유하여 소통하고 발전할 수 있도록 해주세요.
이전: 1부: OpenResty를 사용하여 마이크로서비스 API 게이트웨이를 구축하는 방법 다음: 3부: OpenResty를 사용하여 마이크로서비스 API 게이트웨이를 구축하는 방법