第2部:OpenRestyを使用してマイクロサービスAPIゲートウェイを構築する方法
API7.ai
February 2, 2023
マイクロサービスAPIゲートウェイのコアコンポーネントと抽象化を理解した後、技術選定を開始し、実装に移る時が来ました。今日は、ストレージ、ルーティング、スキーマ、プラグインという4つのコアコンポーネントの技術選定についてそれぞれ見ていきます。
ストレージ
前回の記事で述べたように、ストレージは非常に重要な基盤コンポーネントであり、設定の同期方法、クラスタのスケーリング、高可用性の保証などの核心的な問題に影響を与えます。そのため、選定プロセスの最初に置かれます。
既存のAPIゲートウェイがデータをどこに保存しているかを見てみましょう。KongはPostgreSQLまたはCassandraを使用し、OpenRestyベースのOrangeはMySQLを使用しています。しかし、これらの選択肢には多くの欠点があります。
まず、ストレージは独立した高可用性ソリューションである必要があります。PostgreSQLやMySQLデータベースには独自の高可用性ソリューションがありますが、DBAとマシンリソースも必要であり、障害時の迅速な切り替えは困難です。
次に、設定変更を取得するためにデータベースをポーリングするしかなく、プッシュができません。これにより、データベースリソースの消費が増え、変更のリアルタイム性が低下します。
さらに、履歴バージョンを維持し、ロールバックやアップグレードを考慮する必要があります。例えば、ユーザーが変更をリリースした場合、後続のロールバック操作が必要になることがあり、その際にはコードレベルで2つのバージョンの差分を取って設定をロールバックする必要があります。また、システムのアップグレード時にデータベースのテーブル構造が変更される可能性があるため、新旧バージョンの互換性とデータのアップグレードを考慮する必要があります。
さらに、コードの複雑さが増します。ゲートウェイの機能を実装するだけでなく、前述の3つの欠陥を修正する必要があり、コードの可読性が大幅に低下します。
最後に、デプロイと運用、メンテナンスの難易度が増します。リレーショナルデータベースのデプロイとメンテナンスは簡単な作業ではなく、データベースクラスタの場合さらに複雑になります。迅速なスケーリングができません。
これらのケースに対して、どのように選択すべきでしょうか?
APIゲートウェイの元の要件に戻りましょう。URI、プラグインパラメータ、アップストリームアドレスなどの単純な設定情報が保存されます。複雑な結合操作は必要なく、厳密なトランザクション保証も必要ありません。この場合、リレーショナルデータベースを使用するのは「鶏を牛刀で裂く」ようなものではないでしょうか?
実際、K8sの使用を最小限に抑え、etcdに近づけることが正しい選択です。
- APIゲートウェイの設定データの変更頻度は高くないため、etcdの性能は十分です。
- クラスタリングと動的スケーリングはetcdの固有の利点です。
- etcdには
watchインターフェースもあるため、変更を取得するためにポーリングする必要はありません。
etcdの信頼性を証明するもう一つの事実は、K8sシステムで設定を保存するためのデフォルトの選択肢であり、APIゲートウェイよりもはるかに複雑なシナリオで検証されていることです。
ルーティング
ルーティングも重要な技術選定です。すべてのリクエストはルートによってフィルタリングされ、ロードする必要のあるプラグインのリストが取得され、順番に実行され、指定されたアップストリームに転送されます。ただし、ルーティングルールが多くなる可能性があるため、ここでのルーティングの技術選定ではアルゴリズムの時間計算量に焦点を当てる必要があります。
まず、OpenRestyの下で利用可能なルートを見てみましょう。awesome-restyプロジェクトでそれぞれを調べてみます。このプロジェクトには特別なルーティングライブラリがあります:
• lua-resty-route — OpenResty用のURLルーティングライブラリで、複数のルートマッチャー、ミドルウェア、HTTPおよびWebSocketハンドラーをサポート • router.lua — Lua用のシンプルなルーターで、URLをマッチングし、Lua関数を実行 • lua-resty-r3 — libr3のOpenResty実装で、libr3は高性能なパスディスパッチライブラリ。ルートパスをプレフィックスツリー(トライ)にコンパイルし、起動時に構築されたプレフィックストライを使用してルートを効率的にディスパッチ • lua-resty-libr3 — libr3ベースの高性能パスディスパッチライブラリ
ご覧の通り、これには4つのルーティングライブラリの実装が含まれています。残念ながら、最初の2つのルーティングは純粋なLua実装であり、比較的シンプルで、まだ世代の要件に達していない機能が多く欠けています。
後者の2つのライブラリは、実際にはCライブラリlibr3をFFIでラップしたものであり、libr3自体はプレフィックスツリーを使用しています。このアルゴリズムは保存されたルールの数Nとは関係なく、マッチングデータの長さKのみに関係するため、時間計算量はO(K)です。
しかし、libr3には欠点もあります。そのマッチングルールは、おなじみのNGINXのlocationとは異なり、コールバックをサポートしていません。これにより、リクエストヘッダー、クッキー、NGINX変数に基づいてルーティングの条件を設定する方法がなく、APIゲートウェイのシナリオには十分な柔軟性がありません。
しかし、awesome-restyから使用可能なルーティングライブラリを見つけられなかったとしても、libr3の実装は新しい方向性を示しています。CでプレフィックスツリーとFFIラッパーを実装すれば、時間計算量とコードのパフォーマンスの点で最適解に近づくはずです。
ちょうど、Redisの作者がラディックスツリーのC実装をオープンソース化しており、これは圧縮プレフィックスツリーです。その足跡をたどると、OpenRestyで利用可能なraxのFFIラッパーライブラリも見つけることができます。以下のサンプルコードがあります:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
ご覧の通り、lua-resty-radixtreeはURI、ホスト、HTTPメソッド、HTTPヘッダー、NGINX変数、IPアドレスなど、複数の次元でルート検索をサポートしています。また、基本ツリーの時間計算量はO(K)であり、一般的に使用されるトラバーサル + ハッシュキャッシュアプローチよりもはるかに効率的です。
スキーマ
スキーマの選択ははるかに簡単です。以前紹介したlua-rapidjsonは非常に良い選択肢です。この部分のために独自に書く必要はなく、JSONスキーマは十分に強力です。以下は簡単な例です。
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
プラグイン
ストレージ、ルーティング、スキーマの基盤が整ったことで、プラグインの上位層をどのように実装すべきかがはるかに明確になりました。プラグインでは使用できる既存のオープンソースライブラリはありません。自分たちで実装する必要があります。プラグインを設計する際には、主に3つの側面を明確に考慮する必要があります。
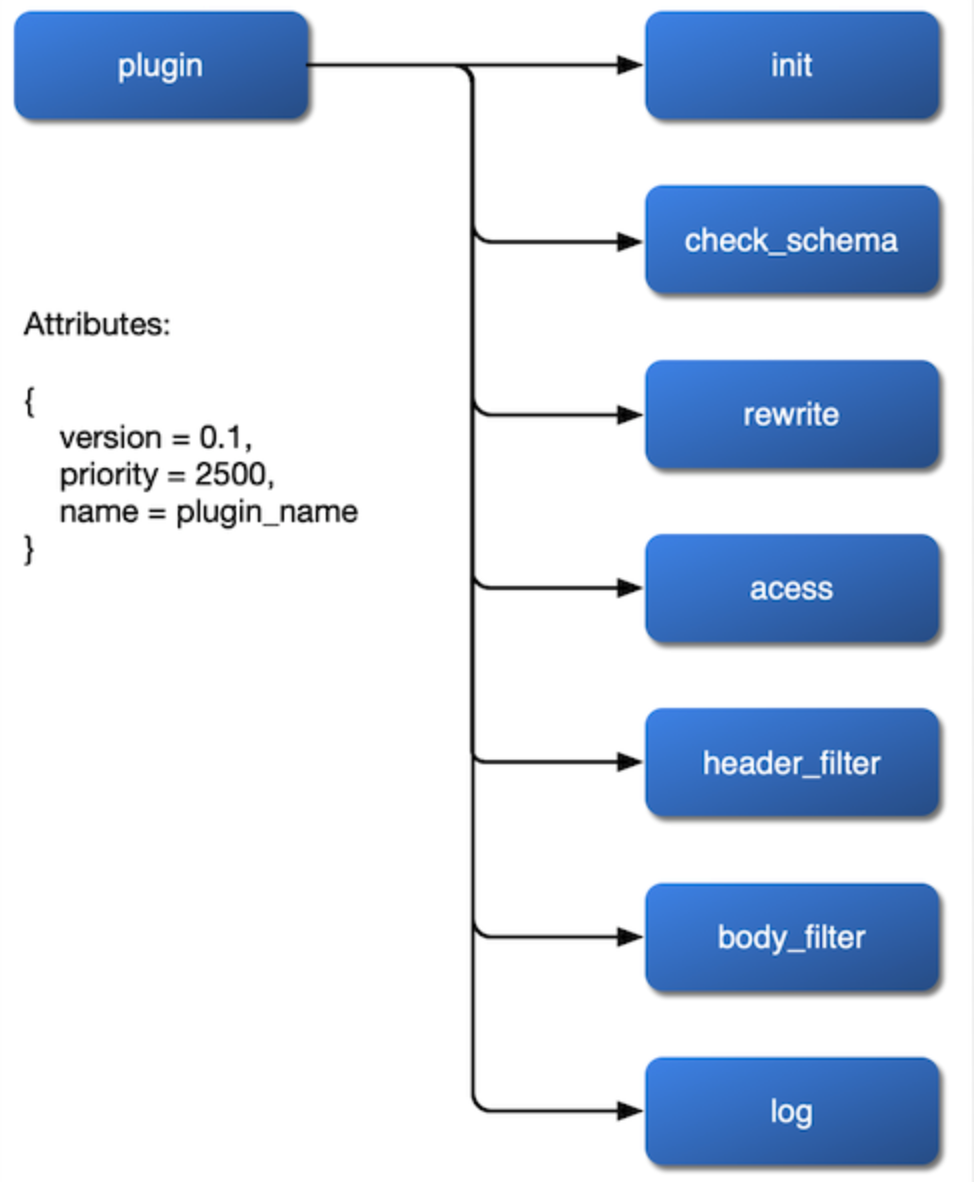
まず、どのようにマウントするかです。プラグインをrewrite、access、header filter、body filter、logフェーズにマウントし、さらにbalancerステージで独自のロードバランシングアルゴリズムを設定できるようにしたいと考えています。そのため、NGINX設定ファイルでこれらのステージを公開し、プラグインの実装でインターフェースを開放する必要があります。
次に、設定変更をどのように取得するかです。リレーショナルデータベースの制約がないため、プラグインパラメータの変更はetcdのwatchを通じて実装できます。これにより、フレームワークコードのロジックがはるかに透明で理解しやすくなります。
最後に、プラグインの優先順位を考慮する必要があります。例えば、認証とレートリミットのどちらを先に実行すべきか?ルートにバインドされたプラグインとサービスにバインドされた別のプラグインの間に競合条件がある場合、どちらを優先すべきか?これらはすべて、適切に考慮する必要があることです。
プラグインのこれら3つの問題を整理した後、プラグインの内部のフローチャートを得ることができます:
{kind=link}
インフラストラクチャ
これらのマイクロサービスAPIゲートウェイの重要なコンポーネントが決定されると、ユーザーリクエストの処理フローが確定します。ここで、このプロセスを示す図を描きました:
{kind=link}
この図から、ユーザーリクエストがAPIゲートウェイに入ると、
- まず、リクエストメソッド、URI、ホスト、リクエストヘッダーの条件に基づいてルーティングルールがマッチングされます。ルーティングルールにヒットすると、etcdから対応するプラグインリストが取得されます。
- 次に、ローカルで開いているプラグインリストと交差させ、実行可能な最終的なプラグインリストを取得します。
- そして、プラグインの優先順位に従って順番に実行します。
- 最後に、アップストリームのヘルスチェックとロードバランシングアルゴリズムに従ってリクエストが送信されます。
アーキテクチャ設計が完了すると、具体的なコードを書く準備が整います。これは実際に家を建てるようなものです。設計図と堅固な基盤があって初めて、レンガやタイルを積む具体的な作業に取り掛かることができます。
まとめ
実際、これら2つの記事を通じて、製品の位置付けと技術選定という最も重要な2つのことを行いました。これらは具体的なコーディング実装よりも重要です。より慎重に検討し、選択してください。
では、実際の仕事でAPIゲートウェイを使用したことはありますか?あなたの会社ではどのようにAPIゲートウェイを選定していますか?ぜひメッセージを残して、あなたの経験と学びを共有してください。また、この記事をより多くの人と共有して、コミュニケーションと進歩を図ってください。
前回:第1部:OpenRestyを使用してマイクロサービスAPIゲートウェイを構築する方法 次回:第3部:OpenRestyを使用してマイクロサービスAPIゲートウェイを構築する方法