الجزء الثاني: كيفية بناء بوابة API للخدمات المصغرة باستخدام OpenResty
API7.ai
February 2, 2023
بعد فهم المكونات الأساسية والتجريدات الخاصة ببوابة واجهة برمجة التطبيقات (API) للخدمات الصغيرة، حان الوقت لبدء وتنفيذ الاختيار التقني. اليوم، سننظر في الاختيار التقني للمكونات الأساسية الأربعة على التوالي: التخزين، التوجيه، المخطط، والإضافات.
التخزين
كما ذكرنا في المقال السابق، التخزين هو مكون أساسي مهم جدًا في القاع، وسيؤثر على القضايا الأساسية مثل كيفية مزامنة التكوين، كيفية توسيع نطاق الكتلة، وكيفية ضمان التوفر العالي، لذا نضعه في بداية عملية الاختيار.
لنلقي نظرة على المكان الذي تخزن فيه بوابات API الحالية بياناتها: Kong في PostgreSQL أو Cassandra. وOrange، أيضًا بناءً على OpenResty، في MySQL. ومع ذلك، هذه الخيارات لها العديد من العيوب.
أولاً، يحتاج التخزين إلى أن يكون حلًا منفصلاً للتوفر العالي. قواعد بيانات PostgreSQL وMySQL لديها حلولها الخاصة للتوفر العالي. ومع ذلك، ستحتاج أيضًا إلى DBA وموارد الآلة، ومن الصعب القيام بتبديل سريع في حالة الفشل.
ثانيًا، يمكننا فقط استطلاع قاعدة البيانات للحصول على تغييرات التكوين ولا يمكننا القيام بالدفع. مرة أخرى، هذا سيزيد من استهلاك موارد قاعدة البيانات ويقلل من الأداء الفعلي للتغييرات.
ثالثًا، يجب عليك الحفاظ على إصداراتك التاريخية والنظر في التراجع والترقيات. على سبيل المثال، إذا قام المستخدم بإصدار تغيير، قد تكون هناك عمليات تراجع لاحقة، وفي هذه الحالة تحتاج إلى إجراء الفرق بين الإصدارين على مستوى الكود لتراجع التكوين. أيضًا، عند ترقية النظام، قد يتم تعديل هيكل جدول قاعدة البيانات، لذا يجب على الكود أن يأخذ في الاعتبار توافق الإصدارات القديمة والجديدة وترقيات البيانات.
رابعًا، يزيد من تعقيد الكود. بالإضافة إلى تنفيذ وظيفة البوابة، تحتاج إلى تصحيح العيوب الثلاثة الأولى للكود، مما يجعل الكود أقل قابلية للقراءة بشكل واضح.
خامسًا، يزيد من صعوبة النشر والتشغيل، والصيانة. نشر وصيانة قاعدة بيانات علائقية ليست مهمة بسيطة، وهي أكثر تعقيدًا إذا كانت كتلة قاعدة بيانات. لا يمكننا القيام بالتوسع السريع.
كيف يجب أن نختار لهذه الحالات؟
لنعد إلى المتطلبات الأصلية لبوابة API، حيث يتم تخزين معلومات التكوين البسيطة، مثل URI، معلمات الإضافات، عناوين المصادر العلوية، إلخ. لا توجد عمليات join معقدة مطلوبة، ولا توجد ضمانات صارمة للتعاملات. في هذه الحالة، استخدام قاعدة بيانات علائقية ليس "قتل الدجاجة بسكين الذبح"، أليس كذلك؟
في الواقع، تقليل استخدام K8s والاقتراب أكثر من etcd هو الخيار الصحيح.
- عدد التغييرات في الثانية في بيانات التكوين لبوابة API ليس كبيرًا، مما يتيح أداءً كافيًا لـ etcd.
- التجميع والتوسع الديناميكي هما مزايا متأصلة في etcd.
- etcd لديها أيضًا واجهة
watch، لذا لا تحتاج إلى الاستطلاع للحصول على التغييرات.
شيء آخر يثبت موثوقية etcd هو أنها بالفعل الخيار الافتراضي لحفظ التكوينات في نظام K8s وتم التحقق منها في العديد من السيناريوهات الأكثر تعقيدًا من بوابات API.
التوجيه
التوجيه هو أيضًا اختيار تقني مهم، وجميع الطلبات يتم تصفيتها عبر المسار إلى قائمة الإضافات التي تحتاج إلى تحميلها، تشغيلها واحدة تلو الأخرى، ثم إعادة توجيهها إلى المصدر العلوي المحدد. ومع ذلك، مع الأخذ في الاعتبار أنه قد يكون هناك المزيد من قواعد التوجيه، نحتاج إلى التركيز على تعقيد الوقت للخوارزمية للاختيار التقني للتوجيه هنا.
لنبدأ بالنظر إلى المسارات المتاحة بسهولة تحت OpenResty. ثم، كالعادة، لنبحث عن كل منها في مشروع awesome-resty، الذي يحتوي على مكتبات توجيه خاصة:
• lua-resty-route — مكتبة توجيه URL لـ OpenResty تدعم عدة مطابقات للمسارات، middleware، ومعالجات HTTP وWebSockets من بين ميزاتها • router.lua — موجه بسيط لـ Lua، يطابق URLs وينفذ وظائف Lua • lua-resty-r3 — تنفيذ OpenResty لـ libr3، libr3 هي مكتبة عالية الأداء لإرسال المسارات. تقوم بتحويل مساراتك إلى شجرة بادئة (trie). باستخدام الشجرة البادئة المبنية في وقت البدء، يمكنك إرسال مساراتك بكفاءة • lua-resty-libr3 — مكتبة عالية الأداء لإرسال المسارات بناءً على libr3 لـ OpenResty
كما ترون، هذا يحتوي على تنفيذات لأربع مكتبات توجيه. لسوء الحظ، أول مسارين هما تنفيذات Lua بحتة، وهي بسيطة نسبيًا، لذا هناك العديد من الميزات المفقودة التي لم تصل بعد إلى متطلبات الجيل.
المكتبتان الأخيرتان هما في الواقع بناءً على مكتبة C libr3 مع طبقة تغليف باستخدام FFI، بينما libr3 نفسها تستخدم شجرة بادئة. هذه الخوارزمية لا علاقة لها بالرقم N من القواعد المخزنة ولكن فقط مع الطول K للبيانات المطابقة، لذا تعقيد الوقت هو O(K).
ومع ذلك، libr3 لها عيوبها. قواعد المطابقة الخاصة بها تختلف عن قواعد NGINX location المألوفة، ولا تدعم الاستدعاءات. هذا يتركنا بدون طريقة لتعيين شروط التوجيه بناءً على رؤوس الطلبات، الكوكيز، ومتغيرات NGINX، وهو أمر غير مرن بما يكفي لسيناريوهات بوابة API.
ومع ذلك، على الرغم من أن محاولاتنا للعثور على مكتبة توجيه قابلة للاستخدام من awesome-resty لم تنجح، فإن تنفيذ libr3 يشير لنا إلى اتجاه جديد: تنفيذ أشجار البادئة وFFI wrappers في C، والذي يجب أن يقترب من الحل الأمثل من حيث تعقيد الوقت وأداء الكود.
كما حدث، قام مؤلفو Redis بفتح مصدر تنفيذ C لشجرة radix، وهي شجرة بادئة مضغوطة. باتباع المسار، يمكننا أيضًا العثور على مكتبة FFI wrapper لـ rax المتاحة في OpenResty، والتي تحتوي على الكود التالي كمثال:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
كما ترون، lua-resty-radixtree تدعم أبعادًا متعددة للبحث عن المسار بناءً على URI، المضيف، طريقة HTTP، رأس HTTP، متغيرات NGINX، عنوان IP، إلخ. أيضًا، تعقيد الوقت لشجرة الأساس هو O(K)، وهو أكثر كفاءة بكثير من النهج الشائع traversal + hash cache.
المخطط
اختيار المخطط أسهل بكثير. lua-rapidjson التي قدمناها سابقًا هي خيار جيد جدًا. لا تحتاج إلى كتابة واحد لهذا الجزء؛ مخطط JSON قوي بما يكفي. فيما يلي مثال بسيط.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
الإضافات
مع الأساس السابق للتخزين، التوجيه، والمخطط، يصبح أكثر وضوحًا كيف يجب تنفيذ الطبقة العليا من الإضافات. لا توجد مكتبات مفتوحة المصدر جاهزة للاستخدام في الإضافات. نحتاج إلى تنفيذها بأنفسنا. عند تصميم الإضافات، هناك ثلاثة جوانب رئيسية نحتاج إلى النظر فيها بوضوح.
أول شيء هو كيفية تركيبها. نريد أن يتم تركيب الإضافة على مراحل rewrite، access، header filer، body filter، وlog وحتى إعداد خوارزمية موازنة الحمل الخاصة بها في مرحلة balancer. لذا، يجب أن نعرض هذه المراحل في ملف تكوين NGINX ونترك الواجهة مفتوحة في تنفيذ الإضافة.
التالي هو كيفية الحصول على تغييرات التكوين. نظرًا لعدم وجود قيود لقاعدة البيانات العلائقية، يمكن تنفيذ تغييرات معلمات الإضافة عبر watch لـ etcd، مما يجعل منطق إطار العمل الكلي أكثر وضوحًا وسهولة في الفهم.
أخيرًا، نحتاج إلى النظر في أولوية الإضافات. على سبيل المثال، أي إضافة يجب تنفيذها أولاً؟ للتحقق من الهوية أو تحديد التدفق والسرعة؟ عندما يكون هناك تنافس بين إضافة مرتبطة بمسار وإضافة أخرى مرتبطة بخدمة، أي واحدة يجب أن تأخذ الأولوية؟ هذه كلها أشياء نحتاج إلى النظر فيها.
بعد فرز هذه القضايا الثلاثة للإضافة، يمكننا الحصول على مخطط تدفق داخلي للإضافة:
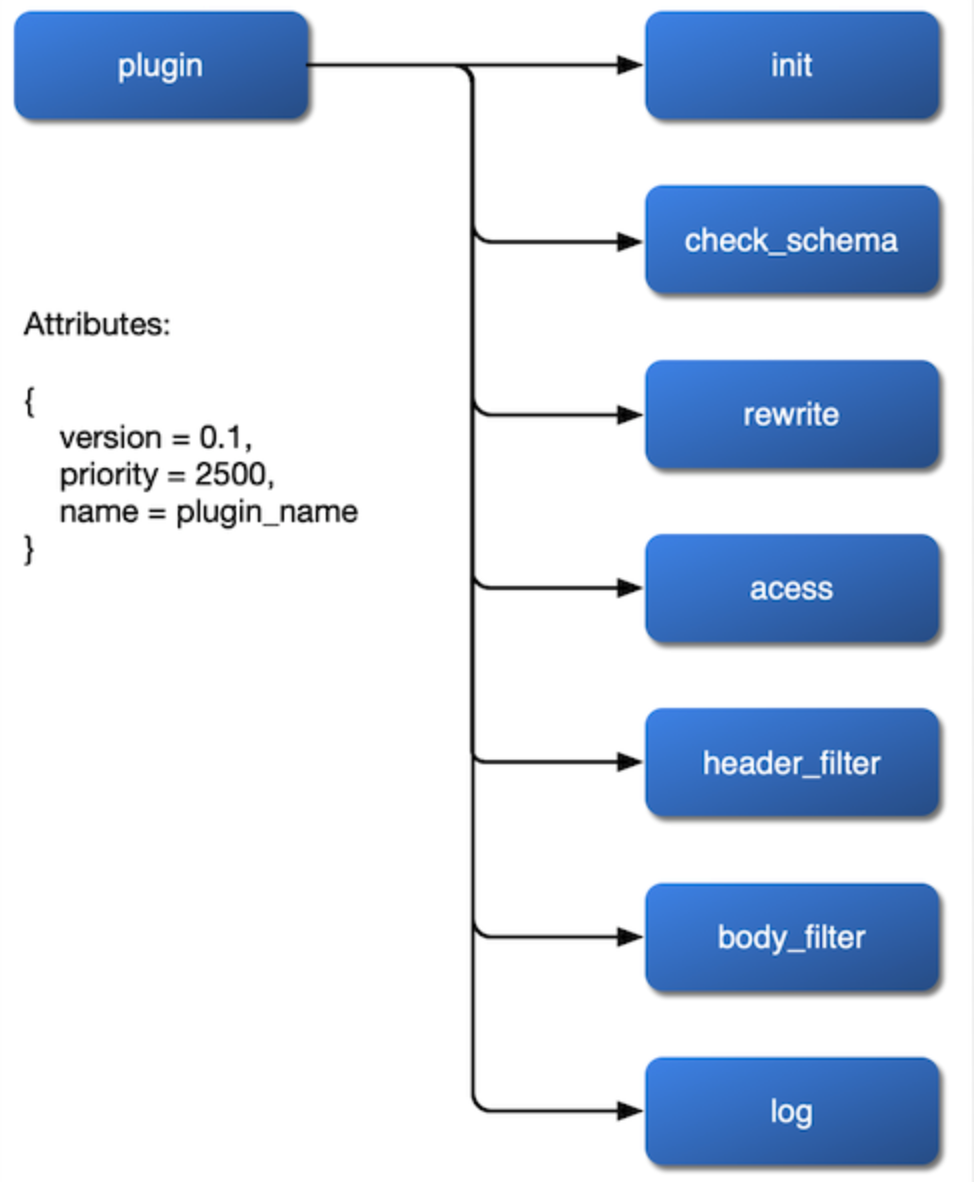{kind=link}
البنية التحتية
بشكل طبيعي، عندما يتم تحديد هذه المكونات الحرجة لبوابة API للخدمات الصغيرة، سيتم تسوية تدفق معالجة طلبات المستخدم. هنا أرسم مخططًا لإظهار هذه العملية:
مخطط تدفق معالجة طلبات المستخدم
{kind=link}
من هذا الشكل، يمكننا أن نرى أنه عندما يدخل طلب المستخدم إلى بوابة API،
- أولاً، سيتم مطابقة قواعد التوجيه بناءً على طرق الطلب، URI، المضيف، وشروط رأس الطلب. إذا تمت مطابقة قاعدة توجيه، ستتم الحصول على قائمة الإضافات المقابلة من etcd.
- ثم، يتم تقاطعها مع قائمة الإضافات المفتوحة محليًا للحصول على قائمة الإضافات النهائية التي يمكن تشغيلها.
- ثم يتم تشغيل الإضافات واحدة تلو الأخرى وفقًا لأولويتها.
- أخيرًا، يتم إرسال الطلب إلى المصدر العلوي وفقًا لفحص صحة المصدر العلوي وخوارزمية موازنة الحمل.
سنكون جاهزين لكتابة الكود المحدد عند اكتمال تصميم الهندسة المعمارية. هذا في الواقع يشبه بناء منزل. فقط بعد أن يكون لديك المخطط والأساس المتين يمكنك القيام بالعمل الملموس لبناء الطوب والبلاط.
الخلاصة
في الواقع، من خلال دراسة هذين المقالين، قمنا بعمل أهم شيئين: تحديد المنتج والاختيار التقني، وهما أكثر أهمية من تنفيذ الكود المحدد. يرجى التفكير والاختيار بعناية أكبر.
لذا، هل سبق لك استخدام بوابة API في عملك الفعلي؟ كيف تختار شركتك بوابة API؟ مرحبًا بترك رسالة ومشاركة تجربتك ومكاسبك معي. أنت أيضًا مرحب بك بمشاركة هذه المقالة مع المزيد من الأشخاص حتى تتمكن من التواصل والتقدم.
السابق: الجزء 1: كيفية بناء بوابة API للخدمات الصغيرة باستخدام OpenResty التالي: الجزء 3: كيفية بناء بوابة API للخدمات الصغيرة باستخدام OpenResty