Часть 2: Как создать API-шлюз для микросервисов с использованием OpenResty
API7.ai
February 2, 2023
После понимания основных компонентов и абстракций API-шлюза для микросервисов, настало время приступить к выбору и реализации технических решений. Сегодня мы рассмотрим технический выбор для четырех основных компонентов: хранилище, маршрутизация, схема и плагины.
Хранилище
Как упоминалось в предыдущей статье, хранилище является очень важным базовым компонентом на нижнем уровне, который влияет на ключевые вопросы, такие как синхронизация конфигурации, масштабирование кластера и обеспечение высокой доступности. Поэтому мы начинаем процесс выбора именно с него.
Давайте посмотрим, где существующие API-шлюзы хранят свои данные: Kong использует PostgreSQL или Cassandra, а Orange, также основанный на OpenResty, использует MySQL. Однако эти варианты имеют множество недостатков.
Во-первых, хранилище должно быть отдельным решением с высокой доступностью. PostgreSQL и MySQL имеют свои собственные решения для высокой доступности, но вам также потребуются DBA и машинные ресурсы, и в случае сбоя быстрое переключение будет затруднено.
Во-вторых, мы можем только опрашивать базу данных для получения изменений конфигурации и не можем использовать механизм push. Это увеличивает потребление ресурсов базы данных и снижает оперативность изменений.
В-третьих, вам необходимо поддерживать свои исторические версии и учитывать откаты и обновления. Например, если пользователь выпускает изменение, могут потребоваться последующие операции отката, и в этот момент вам нужно будет выполнить сравнение двух версий на уровне кода для отката конфигурации. Также при обновлении системы может измениться структура таблиц базы данных, поэтому код должен учитывать совместимость старых и новых версий и обновление данных.
В-четвертых, это увеличивает сложность кода. В дополнение к реализации функциональности шлюза, вам нужно исправлять первые три недостатка кода, что явно снижает читаемость кода.
В-пятых, это увеличивает сложность развертывания, эксплуатации и обслуживания. Развертывание и поддержка реляционной базы данных — это не простая задача, а если это кластер базы данных, то еще сложнее. Мы не можем быстро масштабироваться.
Как же нам выбрать подходящее решение для этих случаев?
Давайте вернемся к исходным требованиям API-шлюза, где хранится простая информация о конфигурации, такая как URI, параметры плагинов, адреса upstream и т.д. Здесь не требуются сложные операции соединения и строгие гарантии транзакций. В этом случае использование реляционной базы данных — это "стрельба из пушки по воробьям", не так ли?
На самом деле, минимизация использования K8s и выбор etcd — это правильное решение.
- Количество изменений в секунду в данных конфигурации API-шлюза невелико, что обеспечивает достаточную производительность для etcd.
- Кластеризация и динамическое масштабирование — это встроенные преимущества etcd.
- etcd также имеет интерфейс
watch, поэтому вам не нужно опрашивать базу данных для получения изменений.
Еще одно доказательство надежности etcd — это то, что он уже является стандартным выбором для сохранения конфигураций в системе K8s и был проверен в гораздо более сложных сценариях, чем API-шлюзы.
Маршрутизация
Маршрутизация также является важным техническим выбором, и все запросы фильтруются через маршрут к списку плагинов, которые необходимо загрузить, выполнить один за другим, а затем перенаправить на указанный upstream. Однако, учитывая, что может быть много правил маршрутизации, нам нужно сосредоточиться на временной сложности алгоритма для технического выбора маршрутизации.
Давайте сначала посмотрим, какие маршруты доступны в OpenResty. Затем, как обычно, посмотрим каждый из них в проекте awesome-resty, где есть специальные библиотеки для маршрутизации:
• lua-resty-route — Библиотека маршрутизации URL для OpenResty, поддерживающая несколько матчеров маршрутов, middleware и обработчиков HTTP и WebSockets, чтобы упомянуть лишь некоторые из ее функций. • router.lua — Простой маршрутизатор для Lua, который сопоставляет URL и выполняет функции Lua. • lua-resty-r3 — Реализация OpenResty для libr3, libr3 — это высокопроизводительная библиотека для диспетчеризации путей. Она компилирует ваши пути маршрутов в префиксное дерево (trie). Используя построенное префиксное дерево во время запуска, вы можете эффективно диспетчеризировать свои маршруты. • lua-resty-libr3 — Высокопроизводительная библиотека диспетчеризации путей на основе libr3 для OpenResty.
Как видите, здесь представлены реализации четырех библиотек маршрутизации. К сожалению, первые две маршрутизации — это чистая реализация на Lua, которая относительно проста, поэтому в них отсутствует множество функций, которые еще не соответствуют требованиям.
Последние две библиотеки фактически основаны на C-библиотеке libr3 с использованием обертки через FFI, а сама libr3 использует префиксное дерево. Этот алгоритм не зависит от количества правил N, а только от длины K сопоставляемых данных, поэтому временная сложность составляет O(K).
Однако у libr3 есть свои недостатки. Его правила сопоставления отличаются от знакомых NGINX location, и он не поддерживает обратные вызовы. Это оставляет нас без возможности устанавливать условия маршрутизации на основе заголовков запросов, cookies и переменных NGINX, что явно недостаточно гибко для сценариев API-шлюза.
Однако, хотя наши попытки найти пригодную библиотеку маршрутизации в awesome-resty не увенчались успехом, реализация libr3 указывает нам новое направление: реализация префиксных деревьев и оберток FFI на C, что должно приблизиться к оптимальному решению с точки зрения временной сложности и производительности кода.
Как раз авторы Redis открыли исходный код реализации radix tree на C, который является сжатым префиксным деревом. Следуя по следам, мы также можем найти библиотеку-обертку FFI для rax, доступную в OpenResty, с примером кода:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
Как видите, lua-resty-radixtree поддерживает несколько измерений для поиска маршрутов на основе URI, хоста, HTTP-метода, HTTP-заголовка, переменных NGINX, IP-адреса и т.д. Также временная сложность базового дерева составляет O(K), что гораздо эффективнее, чем обычно используемый подход обход + хэш-кэш.
Схема
Выбор схемы гораздо проще. lua-rapidjson, который мы представили ранее, — это очень хороший выбор. Вам не нужно писать свою реализацию для этой части; JSON-схема достаточно мощная. Вот простой пример:
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Плагины
С учетом вышеупомянутой основы хранилища, маршрутизации и схемы, становится гораздо понятнее, как должна быть реализована верхняя часть плагинов. В плагинах нет готовых открытых библиотек для использования. Нам нужно реализовать их самостоятельно. При проектировании плагинов есть три основных аспекта, которые нужно четко продумать.
Первое — это как их монтировать. Мы хотим, чтобы плагин монтировался на этапах rewrite, access, header filter, body filter и log, и даже устанавливал свой алгоритм балансировки нагрузки на этапе balancer. Поэтому мы должны открыть эти этапы в конфигурационном файле NGINX и оставить интерфейс открытым при реализации плагина.
Следующее — как получать изменения конфигурации. Поскольку нет ограничений реляционной базы данных, изменения параметров плагинов могут быть реализованы через watch в etcd, что делает общую логику кода фреймворка гораздо более прозрачной и понятной.
Наконец, нам нужно учитывать приоритет плагинов. Например, какой плагин должен выполняться первым: для аутентификации или для ограничения скорости? Когда возникает состояние гонки между плагином, привязанным к маршруту, и другим плагином, привязанным к сервису, какой из них должен иметь приоритет? Все это нужно учитывать.
После проработки этих трех вопросов плагинов мы можем получить схему внутренней работы плагинов:
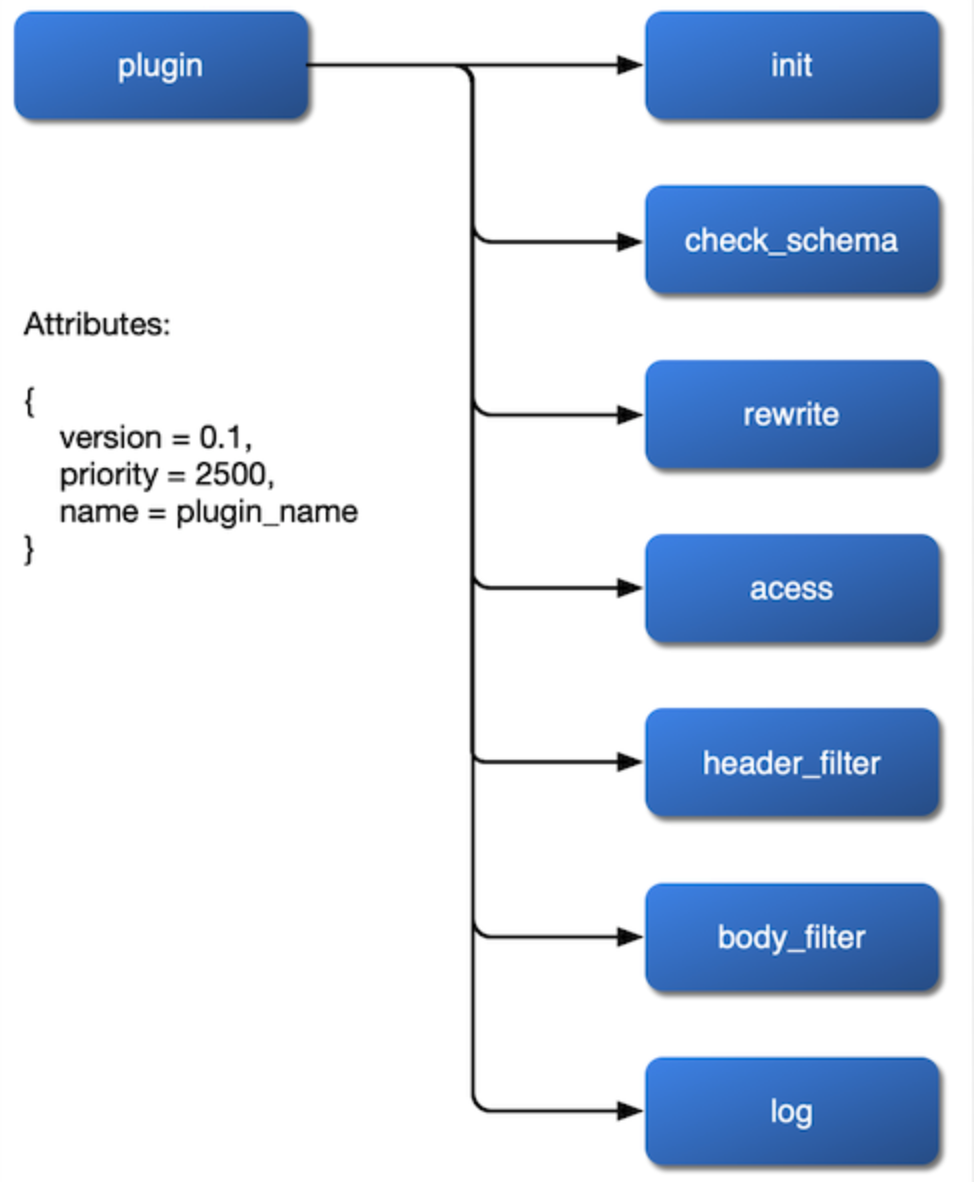{kind=link}
Инфраструктура
Естественно, когда эти ключевые компоненты API-шлюза для микросервисов определены, процесс обработки пользовательских запросов будет установлен. Здесь я нарисовал схему, чтобы показать этот процесс:
Схема обработки пользовательских запросов
{kind=link}
Из этой схемы видно, что когда пользовательский запрос попадает в API-шлюз,
- Сначала правила маршрутизации будут сопоставлены в соответствии с методами запроса, URI, хостом и условиями заголовка запроса. Если правило маршрутизации совпадает, вы получите соответствующий список плагинов из etcd.
- Затем он пересекается с локально открытым списком плагинов, чтобы получить окончательный список плагинов, которые можно запустить.
- После этого плагины выполняются один за другим в соответствии с их приоритетом.
- Наконец, запрос отправляется на upstream в соответствии с проверкой здоровья upstream и алгоритмом балансировки нагрузки.
Когда архитектурный дизайн завершен, мы будем готовы писать конкретный код. Это похоже на строительство дома. Только после того, как у вас есть чертеж и прочный фундамент, можно приступать к конкретной работе по укладке кирпичей и черепицы.
Итог
На самом деле, благодаря изучению этих двух статей, мы выполнили две самые важные задачи: позиционирование продукта и выбор технологий, что более критично, чем конкретная реализация кода. Пожалуйста, подумайте и выбирайте более тщательно.
Итак, использовали ли вы API-шлюз в своей реальной работе? Как ваша компания выбирает API-шлюз? Поделитесь своим опытом и достижениями в комментариях. Также вы можете поделиться этой статьей с другими, чтобы обмениваться опытом и развиваться.
Предыдущая статья: Часть 1: Как построить API-шлюз для микросервисов с использованием OpenResty Следующая статья: Часть 3: Как построить API-шлюз для микросервисов с использованием OpenResty