Bagian 2: Cara Membangun Microservices API Gateway Menggunakan OpenResty
API7.ai
February 2, 2023
Setelah memahami komponen inti dan abstraksi dari gateway API microservices, saatnya untuk memulai dan mengimplementasikan seleksi teknis. Hari ini, kita akan melihat seleksi teknis dari empat komponen inti secara berturut-turut: penyimpanan, routing, skema, dan plugin.
Penyimpanan
Seperti yang disebutkan dalam artikel sebelumnya, penyimpanan adalah komponen dasar yang sangat kritis di bagian bawah, yang akan memengaruhi masalah inti seperti bagaimana menyinkronkan konfigurasi, bagaimana memperluas kluster, dan bagaimana menjamin ketersediaan tinggi, sehingga kami menempatkannya di awal proses seleksi.
Mari kita lihat di mana gateway API yang ada menyimpan datanya: Kong di PostgreSQL atau Cassandra. Dan Orange, yang juga berbasis OpenResty, di MySQL. Namun, opsi-opsi ini memiliki banyak kekurangan.
Pertama, penyimpanan perlu menjadi solusi ketersediaan tinggi yang terpisah. Basis data PostgreSQL dan MySQL memiliki solusi ketersediaan tinggi mereka sendiri. Namun, Anda juga memerlukan DBA dan sumber daya mesin, dan sulit untuk melakukan switchover cepat jika terjadi kegagalan.
Kedua, kita hanya dapat melakukan polling ke basis data untuk mendapatkan perubahan konfigurasi dan tidak dapat melakukan pushing. Sekali lagi, ini akan meningkatkan konsumsi sumber daya basis data dan mengurangi real-time performance dari perubahan.
Ketiga, Anda harus mempertahankan versi historis Anda dan mempertimbangkan rollback dan upgrade. Misalnya, jika pengguna merilis perubahan, mungkin ada operasi rollback berikutnya, di mana Anda perlu melakukan diff antara dua versi pada tingkat kode untuk rollback konfigurasi. Juga, ketika sistem diupgrade, mungkin akan mengubah struktur tabel basis data, sehingga kode harus mempertimbangkan kompatibilitas versi lama dan baru serta upgrade data.
Keempat, ini meningkatkan kompleksitas kode. Selain mengimplementasikan fungsionalitas gateway, Anda perlu menambal tiga cacat pertama dari kode, yang jelas membuat kode jauh kurang mudah dibaca.
Kelima, ini meningkatkan kesulitan dalam deployment, operasi, dan pemeliharaan. Mendeploy dan memelihara basis data relasional bukanlah tugas yang sederhana, dan bahkan lebih rumit jika itu adalah kluster basis data. Kita tidak dapat melakukan scaling cepat.
Bagaimana seharusnya kita memilih untuk kasus-kasus ini?
Mari kita kembali ke kebutuhan awal dari gateway API, di mana informasi konfigurasi sederhana disimpan, seperti URI, parameter plugin, alamat upstream, dll. Tidak ada operasi join yang kompleks yang terlibat, dan tidak ada jaminan transaksi yang ketat diperlukan. Dalam hal ini, menggunakan basis data relasional bukanlah "membunuh ayam dengan pisau sembelih," bukan?
Sebenarnya, meminimalkan penggunaan K8s dan mendekatkannya ke etcd adalah pilihan yang tepat.
- Jumlah perubahan per detik dalam data konfigurasi gateway API tidak besar, yang memungkinkan kinerja yang cukup untuk etcd.
- Clustering dan dynamic scaling adalah keunggulan bawaan dari etcd.
- etcd juga memiliki antarmuka
watch, sehingga Anda tidak perlu melakukan polling untuk mendapatkan perubahan.
Hal lain yang membuktikan keandalan etcd adalah bahwa itu sudah menjadi pilihan default untuk menyimpan konfigurasi dalam sistem K8s dan telah divalidasi untuk banyak skenario yang lebih kompleks daripada gateway API.
Routing
Routing juga merupakan seleksi teknis yang penting, dan semua permintaan difilter oleh rute ke daftar plugin yang perlu dimuat, dijalankan satu per satu, dan kemudian diteruskan ke upstream yang ditentukan. Namun, mengingat bahwa mungkin ada lebih banyak aturan routing, kita perlu fokus pada kompleksitas waktu dari algoritma untuk seleksi teknis routing di sini.
Mari kita mulai dengan melihat rute apa yang tersedia di bawah OpenResty. Kemudian, seperti biasa, mari kita lihat masing-masingnya di proyek awesome-resty, yang memiliki perpustakaan routing khusus:
• lua-resty-route — Perpustakaan routing URL untuk OpenResty yang mendukung beberapa matcher rute, middleware, dan handler HTTP dan WebSockets untuk menyebutkan beberapa fiturnya • router.lua — Router sederhana untuk Lua, mencocokkan URL dan menjalankan fungsi Lua • lua-resty-r3 — Implementasi OpenResty dari libr3, libr3 adalah perpustakaan pengiriman path berkinerja tinggi. Ini mengompilasi path rute Anda menjadi pohon prefix (trie). Dengan menggunakan pohon prefix yang dibangun pada waktu start-up, Anda dapat mengirimkan rute Anda dengan efisiensi • lua-resty-libr3 — Perpustakaan pengiriman path berkinerja tinggi berbasis libr3 untuk OpenResty
Seperti yang Anda lihat, ini berisi implementasi dari empat perpustakaan routing. Sayangnya, dua routing pertama adalah implementasi Lua murni, yang relatif sederhana, sehingga ada cukup banyak fitur yang hilang yang belum memenuhi persyaratan generasi.
Dua perpustakaan terakhir sebenarnya berbasis pada perpustakaan C libr3 dengan lapisan pembungkus menggunakan FFI, sementara libr3 sendiri menggunakan pohon prefix. Algoritma ini tidak ada hubungannya dengan jumlah N dari aturan yang disimpan tetapi hanya dengan panjang K dari data yang cocok, sehingga kompleksitas waktu adalah O(K).
Namun, libr3 memiliki kekurangannya. Aturan pencocokannya berbeda dengan lokasi NGINX yang familiar, dan tidak mendukung callback. Ini membuat kita tidak dapat menetapkan kondisi untuk routing berdasarkan header permintaan, cookie, dan variabel NGINX, yang jelas tidak cukup fleksibel untuk skenario gateway API.
Namun, meskipun upaya kami untuk menemukan perpustakaan routing yang dapat digunakan dari awesome-resty tidak berhasil, implementasi libr3 mengarahkan kita ke arah baru: mengimplementasikan pohon prefix dan pembungkus FFI dalam C, yang seharusnya mendekati solusi optimal dalam hal kompleksitas waktu dan kinerja kode.
Kebetulan, penulis Redis telah membuka sumber implementasi C dari radix tree, yang merupakan pohon prefix terkompresi. Mengikuti jejaknya, kita juga dapat menemukan perpustakaan pembungkus FFI untuk rax yang tersedia di OpenResty, yang memiliki kode contoh berikut:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
Seperti yang Anda lihat, lua-resty-radixtree mendukung beberapa dimensi untuk pencarian rute berdasarkan URI, host, metode HTTP, header HTTP, variabel NGINX, alamat IP, dll. Juga, kompleksitas waktu dari pohon dasar adalah O(K), yang jauh lebih efisien daripada pendekatan traversal + hash cache yang biasa digunakan.
Skema
Memilih skema jauh lebih mudah. lua-rapidjson yang kami perkenalkan sebelumnya adalah pilihan yang sangat baik. Anda tidak perlu menulis satu untuk bagian ini; skema JSON sudah cukup kuat. Berikut adalah contoh sederhana.
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
Plugin
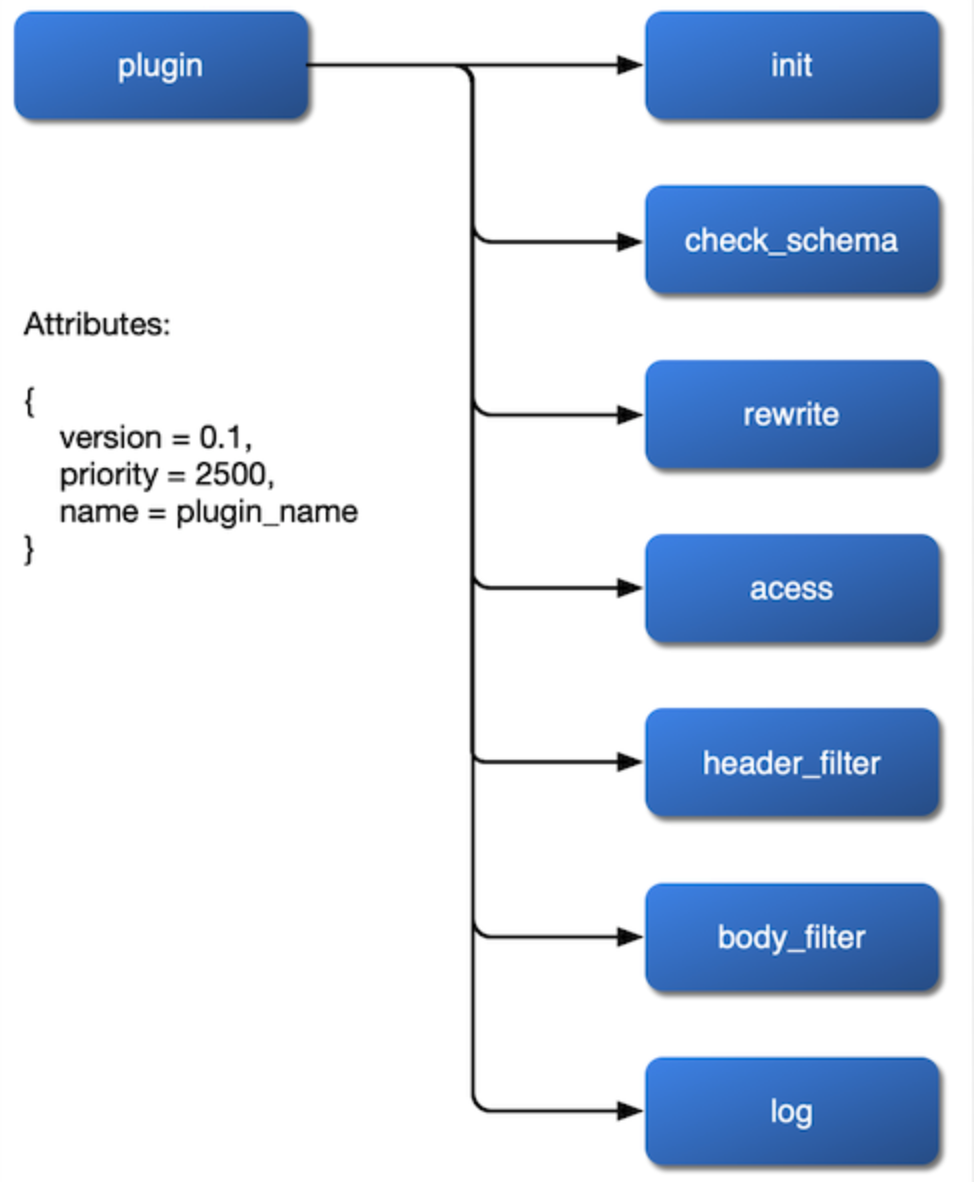
Dengan dasar penyimpanan, routing, dan skema di atas, jauh lebih jelas bagaimana lapisan atas plugin harus diimplementasikan. Tidak ada perpustakaan open source siap pakai yang dapat digunakan dalam plugin. Kita perlu mengimplementasikannya sendiri. Saat merancang plugin, ada tiga aspek utama yang perlu kita pertimbangkan dengan jelas.
Hal pertama adalah bagaimana memuatnya. Kami ingin plugin dimuat ke fase rewrite, access, header filter, body filter, dan log, dan bahkan mengatur algoritma load-balancing sendiri di tahap balancer. Jadi, kita harus mengekspos fase-fase ini dalam file konfigurasi NGINX dan membiarkan antarmuka terbuka dalam implementasi plugin.
Selanjutnya adalah bagaimana mendapatkan perubahan konfigurasi. Karena tidak ada batasan basis data relasional, perubahan pada parameter plugin dapat diimplementasikan melalui watch etcd, yang membuat logika kode kerangka keseluruhan jauh lebih transparan dan mudah dipahami.
Terakhir, kita perlu mempertimbangkan prioritas plugin. Misalnya, plugin mana yang harus dijalankan terlebih dahulu? untuk autentikasi atau pembatasan aliran dan kecepatan? Ketika ada kondisi balapan antara plugin yang terikat ke rute dan plugin lain yang terikat ke layanan, mana yang harus diutamakan? Ini semua adalah hal yang perlu kita pertimbangkan dengan baik.
Setelah menyelesaikan tiga masalah plugin ini, kita bisa mendapatkan diagram alur internal plugin:
{kind=link}
Infrastruktur
Secara alami, ketika komponen kritis dari gateway API microservices ini ditentukan, alur pemrosesan permintaan pengguna akan ditetapkan. Di sini saya menggambar diagram untuk menunjukkan proses ini:
Diagram alur pemrosesan permintaan pengguna
{kind=link}
Dari gambar ini, kita dapat melihat bahwa ketika permintaan pengguna masuk ke gateway API,
- Pertama-tama, aturan routing akan dicocokkan berdasarkan metode permintaan, URI, host, dan kondisi header permintaan. Jika Anda mengenai aturan routing, Anda akan mendapatkan daftar plugin yang sesuai dari etcd.
- Kemudian, itu berpotongan dengan daftar plugin yang dibuka secara lokal untuk mendapatkan daftar plugin akhir yang dapat dijalankan.
- Dan kemudian menjalankan plugin satu per satu sesuai dengan prioritasnya.
- Akhirnya, permintaan dikirim ke upstream sesuai dengan pemeriksaan kesehatan upstream dan algoritma load balancing.
Kita akan siap untuk menulis kode spesifik ketika desain arsitektur selesai. Ini sebenarnya seperti membangun rumah. Hanya setelah Anda memiliki cetak biru dan fondasi yang kuat, Anda dapat melakukan pekerjaan konkret membangun batu bata dan genteng.
Ringkasan
Sebenarnya, melalui studi dari dua artikel ini, kita telah melakukan dua hal paling penting dari penentuan produk dan seleksi teknologi, yang lebih kritis daripada implementasi pengkodean spesifik. Silakan pertimbangkan dan pilih dengan lebih hati-hati.
Jadi, apakah Anda pernah menggunakan gateway API dalam pekerjaan aktual Anda? Bagaimana perusahaan Anda memilih gateway API? Silakan tinggalkan pesan dan bagikan pengalaman dan hasil Anda dengan saya. Anda juga dipersilakan untuk membagikan artikel ini kepada lebih banyak orang sehingga Anda dapat berkomunikasi dan membuat kemajuan.
Sebelumnya: Bagian 1: Cara Membangun Gateway API Microservices Menggunakan OpenResty Berikutnya: Bagian 3: Cara Membangun Gateway API Microservices Menggunakan OpenResty