भाग 2: OpenResty का उपयोग करके एक Microservices API गेटवे कैसे बनाएं
API7.ai
February 2, 2023
माइक्रोसर्विसेस API गेटवे के मूल घटकों और अमूर्तताओं को समझने के बाद, तकनीकी चयन शुरू करने और लागू करने का समय आ गया है। आज, हम चार मूल घटकों के तकनीकी चयन को क्रमशः देखेंगे: स्टोरेज, रूटिंग, स्कीमा, और प्लगइन्स।
स्टोरेज
पिछले लेख में उल्लेख किया गया है, स्टोरेज बहुत ही महत्वपूर्ण बुनियादी घटक है जो नीचे स्थित है, जो कॉन्फ़िगरेशन को कैसे सिंक्रनाइज़ करें, क्लस्टर को कैसे स्केल करें, और उच्च उपलब्धता कैसे सुनिश्चित करें जैसे मुद्दों को प्रभावित करेगा, इसलिए हम इसे चयन प्रक्रिया के शुरुआत में रखते हैं।
आइए देखें कि मौजूदा API गेटवे अपना डेटा कहाँ स्टोर करते हैं: Kong PostgreSQL या Cassandra में। और Orange, जो OpenResty पर आधारित है, MySQL में। हालांकि, इन विकल्पों में कई कमियाँ हैं।
पहला, स्टोरेज को एक अलग उच्च उपलब्धता समाधान होना चाहिए। PostgreSQL और MySQL डेटाबेस के अपने उच्च उपलब्धता समाधान हैं। फिर भी, आपको DBA और मशीन संसाधनों की भी आवश्यकता होगी, और विफलता के मामले में त्वरित स्विचओवर करना मुश्किल होगा।
दूसरा, हम केवल डेटाबेस को पोल करके कॉन्फ़िगरेशन परिवर्तन प्राप्त कर सकते हैं और पुश नहीं कर सकते। फिर से, यह डेटाबेस संसाधन खपत को बढ़ाएगा और परिवर्तनों की वास्तविक समय प्रदर्शन को कम करेगा।
तीसरा, आपको अपने ऐतिहासिक संस्करणों को बनाए रखना होगा और रोलबैक और अपग्रेड पर विचार करना होगा। उदाहरण के लिए, यदि कोई उपयोगकर्ता एक परिवर्तन जारी करता है, तो बाद में रोलबैक ऑपरेशन हो सकते हैं, जिस समय आपको कॉन्फ़िगरेशन रोलबैक के लिए कोड स्तर पर दो संस्करणों के बीच अंतर करने की आवश्यकता होती है। साथ ही, जब सिस्टम अपग्रेड होता है, तो यह डेटाबेस की टेबल संरचना को संशोधित कर सकता है, इसलिए कोड को पुराने और नए संस्करणों की संगतता और डेटा अपग्रेड पर विचार करना होगा।
चौथा, यह कोड की जटिलता को बढ़ाता है। गेटवे की कार्यक्षमता को लागू करने के अलावा, आपको कोड की पहली तीन कमियों को पैच करने की आवश्यकता होती है, जो स्पष्ट रूप से कोड की पठनीयता को कम करता है।
पांचवां, यह तैनाती और संचालन, और रखरखाव की कठिनाई को बढ़ाता है। एक रिलेशनल डेटाबेस को तैनात और बनाए रखना एक सरल कार्य नहीं है, और यदि यह एक डेटाबेस क्लस्टर है तो यह और भी जटिल हो जाता है। हम त्वरित स्केलिंग नहीं कर सकते।
इन मामलों के लिए हमें कैसे चयन करना चाहिए?
आइए API गेटवे की मूल आवश्यकताओं पर वापस जाएं, जहाँ सरल कॉन्फ़िगरेशन जानकारी संग्रहीत की जाती है, जैसे URI, प्लगइन पैरामीटर, अपस्ट्रीम पते, आदि। कोई जटिल जॉइन ऑपरेशन शामिल नहीं है, और कोई सख्त लेन-देन गारंटी की आवश्यकता नहीं है। इस मामले में, एक रिलेशनल डेटाबेस का उपयोग करना "काटने वाले चाकू से मुर्गी को मारना" नहीं है, है ना?
वास्तव में, K8s का उपयोग कम से कम करना और इसे etcd के करीब रखना सही विकल्प है।
- API गेटवे के कॉन्फ़िगरेशन डेटा में प्रति सेकंड परिवर्तनों की संख्या बड़ी नहीं है, जो etcd के लिए पर्याप्त प्रदर्शन सक्षम करती है।
- क्लस्टरिंग और डायनामिक स्केलिंग etcd के अंतर्निहित लाभ हैं।
- etcd में एक
watchइंटरफ़ेस भी है, इसलिए आपको परिवर्तन प्राप्त करने के लिए पोल करने की आवश्यकता नहीं है।
एक और बात जो etcd की विश्वसनीयता साबित करती है, वह यह है कि यह K8s सिस्टम में कॉन्फ़िगरेशन को सहेजने के लिए पहले से ही डिफ़ॉल्ट विकल्प है और API गेटवे से कहीं अधिक जटिल परिदृश्यों के लिए सत्यापित हो चुका है।
रूटिंग
रूटिंग भी एक आवश्यक तकनीकी चयन है, और सभी अनुरोध रूट द्वारा फ़िल्टर किए जाते हैं ताकि लोड किए जाने वाले प्लगइन्स की सूची प्राप्त हो, एक-एक करके चलाए जाएं, और फिर निर्दिष्ट अपस्ट्रीम को फॉरवर्ड किया जाए। हालांकि, यह ध्यान में रखते हुए कि रूटिंग नियम अधिक हो सकते हैं, हमें यहां रूटिंग के तकनीकी चयन के लिए एल्गोरिदम की समय जटिलता पर ध्यान केंद्रित करने की आवश्यकता है।
आइए पहले देखें कि OpenResty के तहत कौन से रूट उपलब्ध हैं। फिर, हमेशा की तरह, आइए awesome-resty प्रोजेक्ट में उनमें से प्रत्येक को देखें, जिसमें विशेष रूटिंग लाइब्रेरीज़ हैं:
• lua-resty-route — OpenResty के लिए एक URL रूटिंग लाइब्रेरी जो कई रूट मैचर्स, मिडलवेयर, और HTTP और WebSockets हैंडलर्स का समर्थन करती है, इसकी कुछ विशेषताओं का उल्लेख करने के लिए • router.lua — Lua के लिए एक बेयरबोन्स रूटर, यह URLs को मैच करता है और Lua फ़ंक्शन्स को निष्पादित करता है • lua-resty-r3 — libr3 OpenResty कार्यान्वयन, libr3 एक उच्च प्रदर्शन पथ डिस्पैचिंग लाइब्रेरी है। यह आपके रूट पथों को एक प्रीफ़िक्स ट्री (ट्राई) में संकलित करता है। स्टार्ट-अप समय में निर्मित प्रीफ़िक्स ट्री का उपयोग करके, आप अपने रूट्स को कुशलता से डिस्पैच कर सकते हैं • lua-resty-libr3 — OpenResty के लिए libr3 पर आधारित उच्च प्रदर्शन पथ डिस्पैचिंग लाइब्रेरी
जैसा कि आप देख सकते हैं, इसमें चार रूटिंग लाइब्रेरीज़ के कार्यान्वयन शामिल हैं। दुर्भाग्य से, पहले दो रूटिंग्स शुद्ध Lua कार्यान्वयन हैं, जो अपेक्षाकृत सरल हैं, इसलिए कई लापता विशेषताएं हैं जो अभी तक पीढ़ी की आवश्यकताओं को पूरा नहीं करती हैं।
बाद की दो लाइब्रेरीज़ वास्तव में C लाइब्रेरी libr3 पर आधारित हैं जिसमें FFI का उपयोग करके एक परत लपेटी गई है, जबकि libr3 स्वयं एक प्रीफ़िक्स ट्री का उपयोग करता है। यह एल्गोरिदम संग्रहीत नियमों की संख्या N से संबंधित नहीं है, बल्कि केवल मिलान डेटा की लंबाई K से संबंधित है, इसलिए समय जटिलता O(K) है।
हालांकि, libr3 की अपनी कमियाँ हैं। इसके मिलान नियम परिचित NGINX लोकेशन से भिन्न हैं, और यह कॉलबैक्स का समर्थन नहीं करता है। इससे हमें अनुरोध हेडर, कुकीज़, और NGINX वेरिएबल्स के आधार पर रूटिंग के लिए शर्तें सेट करने का कोई तरीका नहीं मिलता है, जो API गेटवे परिदृश्यों के लिए स्पष्ट रूप से पर्याप्त लचीला नहीं है।
हालांकि, हालांकि हमारे प्रयास awesome-resty से एक उपयोगी रूटिंग लाइब्रेरी खोजने में असफल रहे, libr3 कार्यान्वयन हमें एक नई दिशा में इंगित करता है: C में प्रीफ़िक्स ट्री और FFI रैपर्स को लागू करना, जो समय जटिलता और कोड प्रदर्शन के मामले में इष्टतम समाधान के करीब होना चाहिए।
संयोग से, Redis के लेखकों ने रेडिक्स ट्री का एक C कार्यान्वयन ओपन-सोर्स किया है, जो एक संपीड़ित प्रीफ़िक्स ट्री है। निशान का पालन करते हुए, हम OpenResty में उपलब्ध rax के लिए FFI रैपर लाइब्रेरी भी पा सकते हैं, जिसमें निम्नलिखित नमूना कोड है:
local radix = require("resty.radixtree") local rx = radix.new({ { path = "/aa", host = "foo.com", method = {"GET", "POST"}, remote_addr = "127.0.0.1", }, { path = "/bb*", host = {"*.bar.com", "gloo.com"}, method = {"GET", "POST", "PUT"}, remote_addr = "fe80:fe80::/64", vars = {"arg_name", "jack"}, } }) ngx.say(rx:match("/aa", {host = "foo.com", method = "GET", remote_addr = "127.0.0.1" }))
जैसा कि आप देख सकते हैं, lua-resty-radixtree URI, होस्ट, HTTP मेथड, HTTP हेडर, NGINX वेरिएबल्स, IP पते, आदि के आधार पर रूट लुकअप के लिए कई आयामों का समर्थन करता है। साथ ही, बेस ट्री की समय जटिलता O(K) है, जो आमतौर पर उपयोग किए जाने वाले ट्रैवर्सल + हैश कैश दृष्टिकोण से कहीं अधिक कुशल है।
स्कीमा
स्कीमा का चयन करना बहुत आसान है। हमारे द्वारा पहले परिचय कराया गया lua-rapidjson एक बहुत अच्छा विकल्प है। आपको इस भाग के लिए एक लिखने की आवश्यकता नहीं है; JSON स्कीमा पर्याप्त शक्तिशाली है। निम्नलिखित एक सरल उदाहरण है।
local schema = { type = "object", properties = { count = {type = "integer", minimum = 0}, time_window = {type = "integer", minimum = 0}, key = {type = "string", enum = {"remote_addr", "server_addr"}}, rejected_code = {type = "integer", minimum = 200, maximum = 600}, }, additionalProperties = false, required = {"count", "time_window", "key", "rejected_code"}, }
प्लगइन
स्टोरेज, रूटिंग, और स्कीमा की उपरोक्त नींव के साथ, यह बहुत स्पष्ट है कि प्लगइन्स की ऊपरी परत को कैसे लागू किया जाना चाहिए। प्लगइन्स में उपयोग करने के लिए कोई तैयार ओपन-सोर्स लाइब्रेरीज़ नहीं हैं। हमें इन्हें स्वयं लागू करने की आवश्यकता है। प्लगइन्स को डिज़ाइन करते समय, हमें तीन मुख्य पहलुओं पर स्पष्ट रूप से विचार करने की आवश्यकता है।
पहली बात यह है कि इसे कैसे माउंट किया जाए। हम चाहते हैं कि प्लगइन rewrite, access, header filer, body filter, और log चरणों में माउंट हो और यहां तक कि balancer चरण में अपना लोड-बैलेंसिंग एल्गोरिदम सेट करे। इसलिए, हमें इन चरणों को NGINX कॉन्फ़िगरेशन फ़ाइल में एक्सपोज़ करना चाहिए और प्लगइन को लागू करते समय इंटरफ़ेस खुला छोड़ना चाहिए।
अगला यह है कि कॉन्फ़िगरेशन परिवर्तन कैसे प्राप्त किए जाएं। चूंकि कोई रिलेशनल डेटाबेस बाधाएं नहीं हैं, प्लगइन पैरामीटर में परिवर्तन etcd के watch के माध्यम से लागू किया जा सकता है, जो समग्र फ्रेमवर्क कोड लॉजिक को बहुत अधिक पारदर्शी और समझने में आसान बनाता है।
अंत में, हमें प्लगइन्स की प्राथमिकता पर विचार करने की आवश्यकता है। उदाहरण के लिए, कौन सा प्लगइन पहले निष्पादित किया जाना चाहिए? प्रमाणीकरण या प्रवाह और गति को सीमित करने के लिए? जब रूट से बाउंड एक प्लगइन और सेवा से बाउंड एक अन्य प्लगइन के बीच एक रेस कंडीशन होती है, तो किसे प्राथमिकता दी जानी चाहिए? ये सभी चीजें हैं जिन पर हमें विचार करने की आवश्यकता है।
प्लगइन के इन तीन मुद्दों को सुलझाने के बाद, हम प्लगइन के आंतरिक भाग का एक फ्लोचार्ट प्राप्त कर सकते हैं:
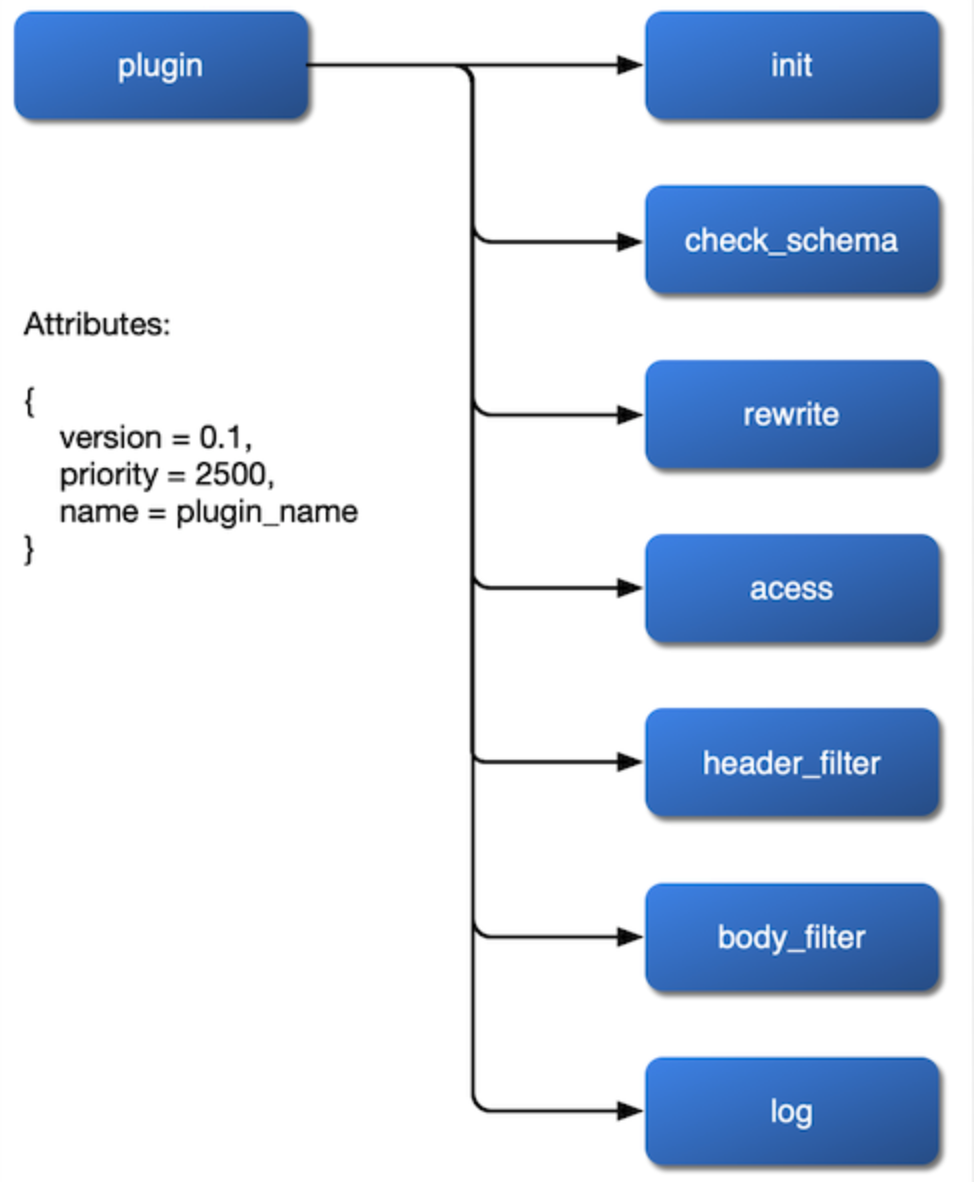{kind=link}
इन्फ्रास्ट्रक्चर
स्वाभाविक रूप से, जब माइक्रोसर्विसेस API गेटवे के ये महत्वपूर्ण घटक निर्धारित हो जाते हैं, तो उपयोगकर्ता अनुरोधों का प्रसंस्करण प्रवाह निर्धारित हो जाएगा। यहां मैं इस प्रक्रिया को दिखाने के लिए एक चित्र बनाता हूं:
उपयोगकर्ता अनुरोधों के प्रसंस्करण प्रवाह का चित्र
{kind=link}
इस चित्र से, हम देख सकते हैं कि जब एक उपयोगकर्ता अनुरोध API गेटवे में प्रवेश करता है,
- सबसे पहले, अनुरोध विधियों, URI, होस्ट, और अनुरोध हेडर शर्तों के अनुसार रूटिंग नियम मिलान किए जाएंगे। यदि आप एक रूटिंग नियम को हिट करते हैं, तो आपको etcd से संबंधित प्लगइन सूची प्राप्त होगी।
- फिर, यह स्थानीय रूप से खोले गए प्लगइन सूची के साथ प्रतिच्छेद करता है ताकि चलाने योग्य अंतिम प्लगइन सूची प्राप्त हो।
- और फिर प्लगइन्स को उनकी प्राथमिकता के अनुसार एक-एक करके चलाया जाता है।
- अंत में, अनुरोध को अपस्ट्रीम स्वास्थ्य जांच और लोड बैलेंसिंग एल्गोरिदम के अनुसार अपस्ट्रीम को भेजा जाता है।
जब आर्किटेक्चर डिज़ाइन पूरा हो जाएगा, तो हम विशिष्ट कोड लिखने के लिए तैयार होंगे। यह वास्तव में एक घर बनाने जैसा है। केवल तभी जब आपके पास ब्लूप्रिंट और ठोस नींव हो, तभी आप ईंट और टाइल बनाने का ठोस काम कर सकते हैं।
सारांश
वास्तव में, इन दो लेखों के अध्ययन के माध्यम से, हमने उत्पाद स्थिति और प्रौद्योगिकी चयन के दो सबसे महत्वपूर्ण कार्य किए हैं, जो विशिष्ट कोडिंग कार्यान्वयन से अधिक महत्वपूर्ण हैं। कृपया अधिक सावधानी से विचार करें और चुनें।
तो, क्या आपने अपने वास्तविक कार्य में कभी API गेटवे का उपयोग किया है? आपकी कंपनी API गेटवे का चयन कैसे करती है? मेरे साथ अपने अनुभव और लाभ साझा करने के लिए संदेश छोड़ने के लिए आपका स्वागत है। आप इस लेख को अधिक लोगों के साथ साझा करने के लिए भी स्वागत कर रहे हैं ताकि आप संवाद कर सकें और प्रगति कर सकें।
पिछला: भाग 1: OpenResty का उपयोग करके माइक्रोसर्विसेस API गेटवे कैसे बनाएं अगला: भाग 3: OpenResty का उपयोग करके माइक्रोसर्विसेस API गेटवे कैसे बनाएं